The Delta Learning Hypothesis: Preference Tuning on Weak Data can Yield Strong Gains
The Delta Learning Hypothesis: Preference Tuning on Weak Data can Yield Strong Gains
Scott Geng, Hamish Ivison, Chun-Liang Li, Maarten Sap, Jerry Li, Ranjay Krishna, Pang Wei Koh
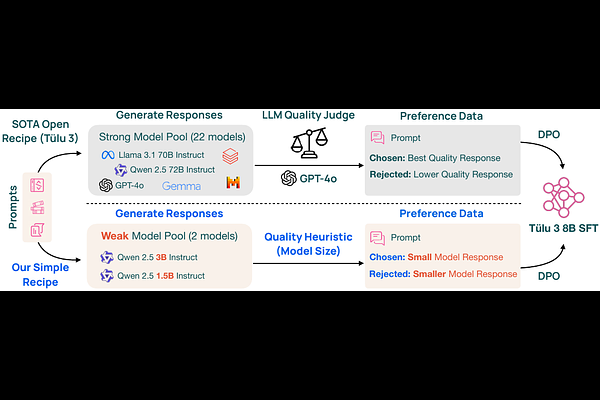
AbstractImprovements in language models are often driven by improving the quality of the data we train them on, which can be limiting when strong supervision is scarce. In this work, we show that paired preference data consisting of individually weak data points can enable gains beyond the strength of each individual data point. We formulate the delta learning hypothesis to explain this phenomenon, positing that the relative quality delta between points suffices to drive learning via preference tuning--even when supervised finetuning on the weak data hurts. We validate our hypothesis in controlled experiments and at scale, where we post-train 8B models on preference data generated by pairing a small 3B model's responses with outputs from an even smaller 1.5B model to create a meaningful delta. Strikingly, on a standard 11-benchmark evaluation suite (MATH, MMLU, etc.), our simple recipe matches the performance of Tulu 3, a state-of-the-art open model tuned from the same base model while relying on much stronger supervisors (e.g., GPT-4o). Thus, delta learning enables simpler and cheaper open recipes for state-of-the-art post-training. To better understand delta learning, we prove in logistic regression that the performance gap between two weak teacher models provides useful signal for improving a stronger student. Overall, our work shows that models can learn surprisingly well from paired data that might typically be considered weak.