LaKo: Knowledge-driven Visual Question Answering via Late Knowledge-to-Text Injection
LaKo: Knowledge-driven Visual Question Answering via Late Knowledge-to-Text Injection
Zhuo Chen, Yufeng Huang, Jiaoyan Chen, Yuxia Geng, Yin Fang, Jeff Pan, Ningyu Zhang, Wen Zhang
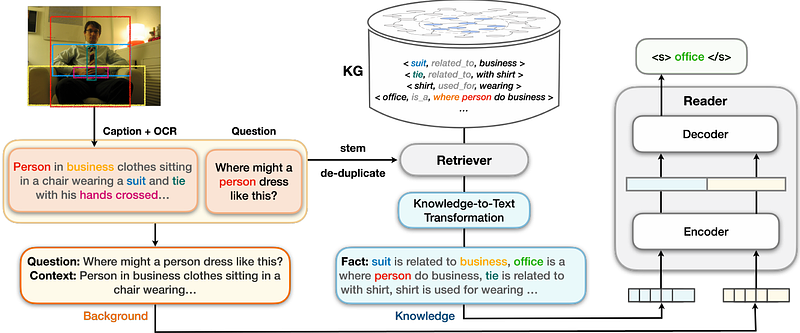
AbstractVisual question answering (VQA) often requires an understanding of visual concepts and language semantics, which relies on external knowledge. Most existing methods exploit pre-trained language models or/and unstructured text, but the knowledge in these resources are often incomplete and noisy. Some other methods prefer to use knowledge graphs (KGs) which often have intensive structured knowledge, but the research is still quite preliminary. In this paper, we propose LaKo, a knowledge-driven VQA method via Late Knowledge-to-text Injection. To effectively incorporate an external KG, we transfer triples into textual format and propose a late injection mechanism for knowledge fusion. Finally we address VQA as a text generation task with an effective encoder-decoder paradigm, which achieves state-of-the-art results on OKVQA dataset.