Pitfalls in Language Models for Code Intelligence: A Taxonomy and Survey
Pitfalls in Language Models for Code Intelligence: A Taxonomy and Survey
Xinyu She, Yue Liu, Yanjie Zhao, Yiling He, Li Li, Chakkrit Tantithamthavorn, Zhan Qin, Haoyu Wang
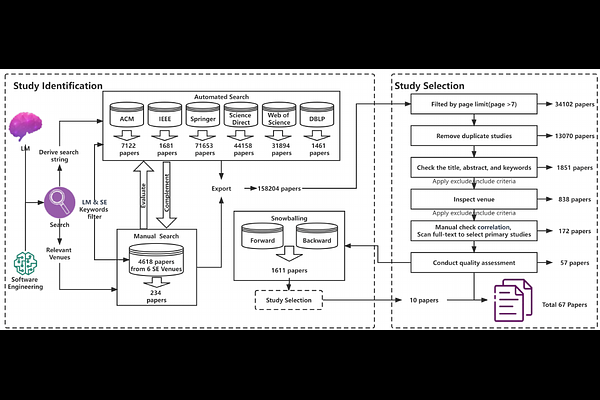
AbstractModern language models (LMs) have been successfully employed in source code generation and understanding, leading to a significant increase in research focused on learning-based code intelligence, such as automated bug repair, and test case generation. Despite their great potential, language models for code intelligence (LM4Code) are susceptible to potential pitfalls, which hinder realistic performance and further impact their reliability and applicability in real-world deployment. Such challenges drive the need for a comprehensive understanding - not just identifying these issues but delving into their possible implications and existing solutions to build more reliable language models tailored to code intelligence. Based on a well-defined systematic research approach, we conducted an extensive literature review to uncover the pitfalls inherent in LM4Code. Finally, 67 primary studies from top-tier venues have been identified. After carefully examining these studies, we designed a taxonomy of pitfalls in LM4Code research and conducted a systematic study to summarize the issues, implications, current solutions, and challenges of different pitfalls for LM4Code systems. We developed a comprehensive classification scheme that dissects pitfalls across four crucial aspects: data collection and labeling, system design and learning, performance evaluation, and deployment and maintenance. Through this study, we aim to provide a roadmap for researchers and practitioners, facilitating their understanding and utilization of LM4Code in reliable and trustworthy ways.