Decomposed Guided Dynamic Filters for Efficient RGB-Guided Depth Completion
Decomposed Guided Dynamic Filters for Efficient RGB-Guided Depth Completion
Yufei Wang, Yuxin Mao, Qi Liu, Yuchao Dai
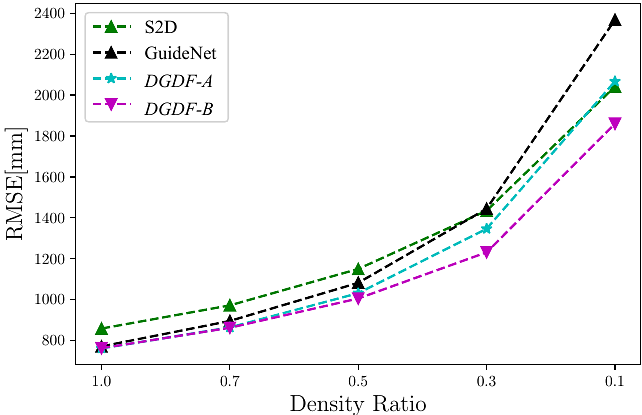
AbstractRGB-guided depth completion aims at predicting dense depth maps from sparse depth measurements and corresponding RGB images, where how to effectively and efficiently exploit the multi-modal information is a key issue. Guided dynamic filters, which generate spatially-variant depth-wise separable convolutional filters from RGB features to guide depth features, have been proven to be effective in this task. However, the dynamically generated filters require massive model parameters, computational costs and memory footprints when the number of feature channels is large. In this paper, we propose to decompose the guided dynamic filters into a spatially-shared component multiplied by content-adaptive adaptors at each spatial location. Based on the proposed idea, we introduce two decomposition schemes A and B, which decompose the filters by splitting the filter structure and using spatial-wise attention, respectively. The decomposed filters not only maintain the favorable properties of guided dynamic filters as being content-dependent and spatially-variant, but also reduce model parameters and hardware costs, as the learned adaptors are decoupled with the number of feature channels. Extensive experimental results demonstrate that the methods using our schemes outperform state-of-the-art methods on the KITTI dataset, and rank 1st and 2nd on the KITTI benchmark at the time of submission. Meanwhile, they also achieve comparable performance on the NYUv2 dataset. In addition, our proposed methods are general and could be employed as plug-and-play feature fusion blocks in other multi-modal fusion tasks such as RGB-D salient object detection.