Mapping Memes to Words for Multimodal Hateful Meme Classification
Mapping Memes to Words for Multimodal Hateful Meme Classification
Giovanni Burbi, Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, Alberto Del Bimbo
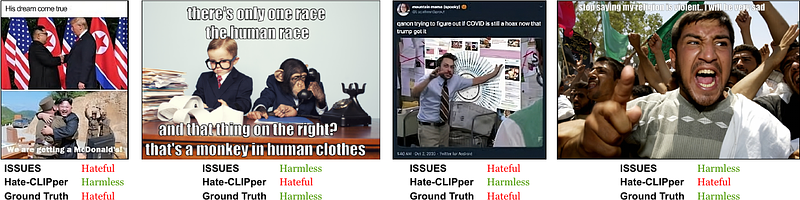
AbstractMultimodal image-text memes are prevalent on the internet, serving as a unique form of communication that combines visual and textual elements to convey humor, ideas, or emotions. However, some memes take a malicious turn, promoting hateful content and perpetuating discrimination. Detecting hateful memes within this multimodal context is a challenging task that requires understanding the intertwined meaning of text and images. In this work, we address this issue by proposing a novel approach named ISSUES for multimodal hateful meme classification. ISSUES leverages a pre-trained CLIP vision-language model and the textual inversion technique to effectively capture the multimodal semantic content of the memes. The experiments show that our method achieves state-of-the-art results on the Hateful Memes Challenge and HarMeme datasets. The code and the pre-trained models are publicly available at https://github.com/miccunifi/ISSUES.