DeepLSH: Deep Locality-Sensitive Hash Learning for Fast and Efficient Near-Duplicate Crash Report Detection
DeepLSH: Deep Locality-Sensitive Hash Learning for Fast and Efficient Near-Duplicate Crash Report Detection
Youcef Remil, Anes Bendimerad, Romain Mathonat, Chedy Raissi, Mehdi Kaytoue
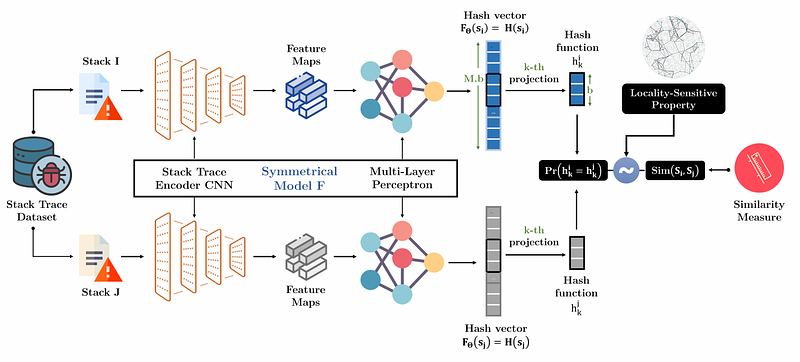
AbstractAutomatic crash bucketing is a crucial phase in the software development process for efficiently triaging bug reports. It generally consists in grouping similar reports through clustering techniques. However, with real-time streaming bug collection, systems are needed to quickly answer the question: What are the most similar bugs to a new one?, that is, efficiently find near-duplicates. It is thus natural to consider nearest neighbors search to tackle this problem and especially the well-known locality-sensitive hashing (LSH) to deal with large datasets due to its sublinear performance and theoretical guarantees on the similarity search accuracy. Surprisingly, LSH has not been considered in the crash bucketing literature. It is indeed not trivial to derive hash functions that satisfy the so-called locality-sensitive property for the most advanced crash bucketing metrics. Consequently, we study in this paper how to leverage LSH for this task. To be able to consider the most relevant metrics used in the literature, we introduce DeepLSH, a Siamese DNN architecture with an original loss function, that perfectly approximates the locality-sensitivity property even for Jaccard and Cosine metrics for which exact LSH solutions exist. We support this claim with a series of experiments on an original dataset, which we make available.