Off-Policy Value-Based Reinforcement Learning for Large Language Models
Off-Policy Value-Based Reinforcement Learning for Large Language Models
Peng-Yuan Wang, Ziniu Li, Tian Xu, Bohan Yang, Tian-Shuo Liu, ChenYang Wang, Xiong-Hui Chen, Yi-Chen Li, Tianyun Yang, Congliang Chen, Yang Yu
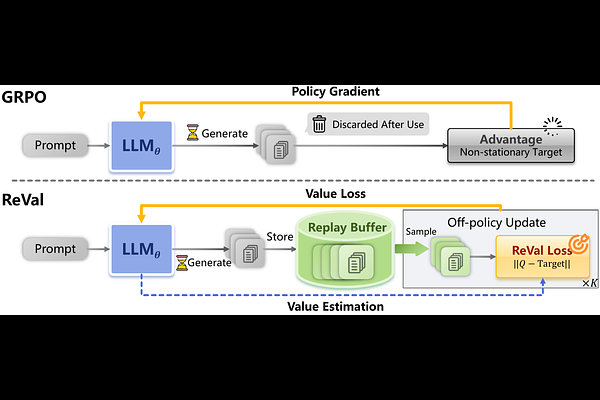
AbstractImproving data utilization efficiency is critical for scaling reinforcement learning (RL) for long-horizon tasks where generating trajectories is expensive. However, the dominant RL methods for LLMs are largely on-policy: they update each batch of data only once, discard it, and then collect fresh samples, resulting in poor sample efficiency. In this work, we explore an alternative value-based RL framework for LLMs that naturally enables off-policy learning. We propose ReVal, a Bellman-update-based method that combines stepwise signals capturing internal consistency with trajectory-level signals derived from outcome verification. ReVal naturally supports replay-buffer-based training, allowing efficient reuse of past trajectories. Experiments on standard mathematical reasoning benchmarks show that ReVal not only converges faster but also outperforms GRPO in final performance. On DeepSeek-R1-Distill-1.5B, ReVal improves training efficiency and achieves improvement of 2.7% in AIME24 and 4.5% in out-of-domain benchmark GPQA over GRPO. These results suggest that value-based RL is a practical alternative to policy-based methods for LLM training.