Masked Space-Time Hash Encoding for Efficient Dynamic Scene Reconstruction
Masked Space-Time Hash Encoding for Efficient Dynamic Scene Reconstruction
Feng Wang, Zilong Chen, Guokang Wang, Yafei Song, Huaping Liu
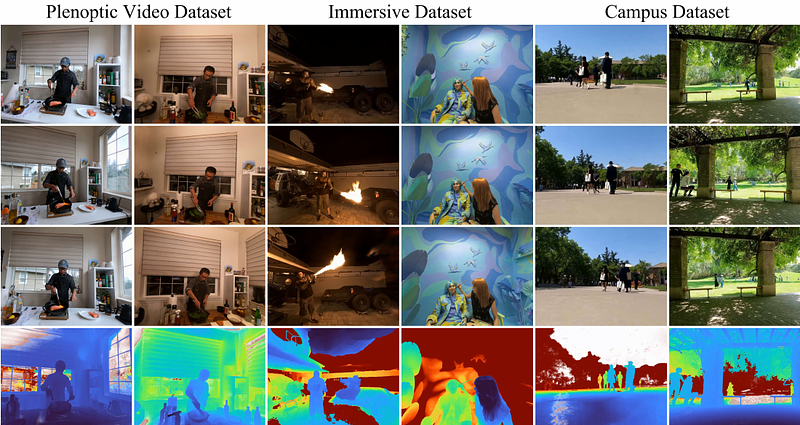
AbstractIn this paper, we propose the Masked Space-Time Hash encoding (MSTH), a novel method for efficiently reconstructing dynamic 3D scenes from multi-view or monocular videos. Based on the observation that dynamic scenes often contain substantial static areas that result in redundancy in storage and computations, MSTH represents a dynamic scene as a weighted combination of a 3D hash encoding and a 4D hash encoding. The weights for the two components are represented by a learnable mask which is guided by an uncertainty-based objective to reflect the spatial and temporal importance of each 3D position. With this design, our method can reduce the hash collision rate by avoiding redundant queries and modifications on static areas, making it feasible to represent a large number of space-time voxels by hash tables with small size.Besides, without the requirements to fit the large numbers of temporally redundant features independently, our method is easier to optimize and converge rapidly with only twenty minutes of training for a 300-frame dynamic scene.As a result, MSTH obtains consistently better results than previous methods with only 20 minutes of training time and 130 MB of memory storage. Code is available at https://github.com/masked-spacetime-hashing/msth