LAiW: A Chinese Legal Large Language Models Benchmark (A Technical Report)
LAiW: A Chinese Legal Large Language Models Benchmark (A Technical Report)
Yongfu Dai, Duanyu Feng, Jimin Huang, Haochen Jia, Qianqian Xie, Yifang Zhang, Weiguang Han, Wei Tian, Hao Wang
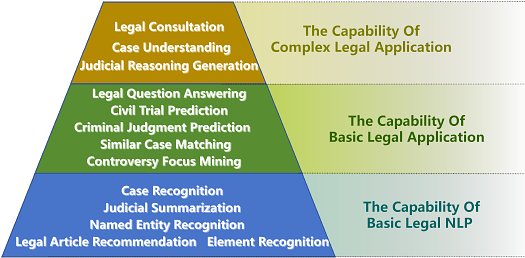
AbstractWith the emergence of numerous legal LLMs, there is currently a lack of a comprehensive benchmark for evaluating their legal abilities. In this paper, we propose the first Chinese Legal LLMs benchmark based on legal capabilities. Through the collaborative efforts of legal and artificial intelligence experts, we divide the legal capabilities of LLMs into three levels: basic legal NLP capability, basic legal application capability, and complex legal application capability. We have completed the first phase of evaluation, which mainly focuses on the capability of basic legal NLP. The evaluation results show that although some legal LLMs have better performance than their backbones, there is still a gap compared to ChatGPT. Our benchmark can be found at URL.