ELRA: Exponential learning rate adaption gradient descent optimization method
ELRA: Exponential learning rate adaption gradient descent optimization method
Alexander Kleinsorge, Stefan Kupper, Alexander Fauck, Felix Rothe
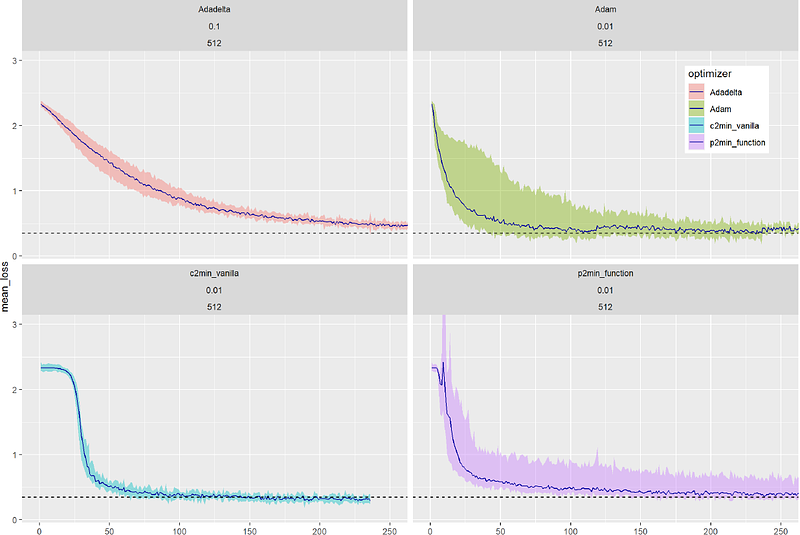
AbstractWe present a novel, fast (exponential rate adaption), ab initio (hyper-parameter-free) gradient based optimizer algorithm. The main idea of the method is to adapt the learning rate $\alpha$ by situational awareness, mainly striving for orthogonal neighboring gradients. The method has a high success and fast convergence rate and does not rely on hand-tuned parameters giving it greater universality. It can be applied to problems of any dimensions n and scales only linearly (of order O(n)) with the dimension of the problem. It optimizes convex and non-convex continuous landscapes providing some kind of gradient. In contrast to the Ada-family (AdaGrad, AdaMax, AdaDelta, Adam, etc.) the method is rotation invariant: optimization path and performance are independent of coordinate choices. The impressive performance is demonstrated by extensive experiments on the MNIST benchmark data-set against state-of-the-art optimizers. We name this new class of optimizers after its core idea Exponential Learning Rate Adaption - ELRA. We present it in two variants c2min and p2min with slightly different control. The authors strongly believe that ELRA will open a completely new research direction for gradient descent optimize.