How does representation impact in-context learning: A exploration on a synthetic task
How does representation impact in-context learning: A exploration on a synthetic task
Jingwen Fu, Tao Yang, Yuwang Wang, Yan Lu, Nanning Zheng
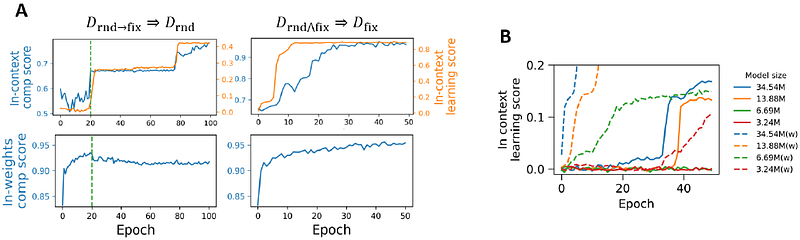
AbstractIn-context learning, i.e., learning from in-context samples, is an impressive ability of Transformer. However, the mechanism driving the in-context learning is not yet fully understood. In this study, we aim to investigate from an underexplored perspective of representation learning. The representation is more complex for in-context learning senario, where the representation can be impacted by both model weights and in-context samples. We refer the above two conceptually aspects of representation as in-weight component and in-context component, respectively. To study how the two components affect in-context learning capabilities, we construct a novel synthetic task, making it possible to device two probes, in-weights probe and in-context probe, to evaluate the two components, respectively. We demonstrate that the goodness of in-context component is highly related to the in-context learning performance, which indicates the entanglement between in-context learning and representation learning. Furthermore, we find that a good in-weights component can actually benefit the learning of the in-context component, indicating that in-weights learning should be the foundation of in-context learning. To further understand the the in-context learning mechanism and importance of the in-weights component, we proof by construction that a simple Transformer, which uses pattern matching and copy-past mechanism to perform in-context learning, can match the in-context learning performance with more complex, best tuned Transformer under the perfect in-weights component assumption. In short, those discoveries from representation learning perspective shed light on new approaches to improve the in-context capacity.