Task-Aware Machine Unlearning and Its Application in Load Forecasting
Task-Aware Machine Unlearning and Its Application in Load Forecasting
Wangkun Xu, Fei Teng
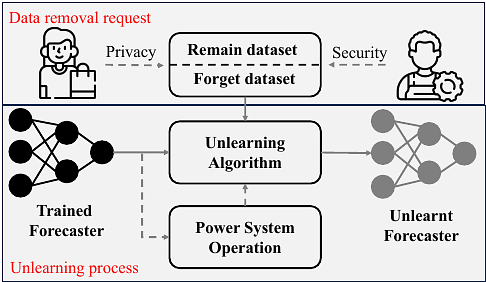
AbstractData privacy and security have become a non-negligible factor in load forecasting. Previous researches mainly focus on training stage enhancement. However, once the model is trained and deployed, it may need to `forget' (i.e., remove the impact of) part of training data if the data is found to be malicious or as requested by the data owner. This paper introduces machine unlearning algorithm which is specifically designed to remove the influence of part of the original dataset on an already trained forecaster. However, direct unlearning inevitably degrades the model generalization ability. To balance between unlearning completeness and performance degradation, a performance-aware algorithm is proposed by evaluating the sensitivity of local model parameter change using influence function and sample re-weighting. Moreover, we observe that the statistic criterion cannot fully reflect the operation cost of down-stream tasks. Therefore, a task-aware machine unlearning is proposed whose objective is a tri-level optimization with dispatch and redispatch problems considered. We theoretically prove the existence of the gradient of such objective, which is key to re-weighting the remaining samples. We test the unlearning algorithms on linear and neural network load forecasters with realistic load dataset. The simulation demonstrates the balance on unlearning completeness and operational cost. All codes can be found at https://github.com/xuwkk/task_aware_machine_unlearning.