Characterizing Speed Performance of Multi-Agent Reinforcement Learning
Characterizing Speed Performance of Multi-Agent Reinforcement Learning
Samuel Wiggins, Yuan Meng, Rajgopal Kannan, Viktor Prasanna
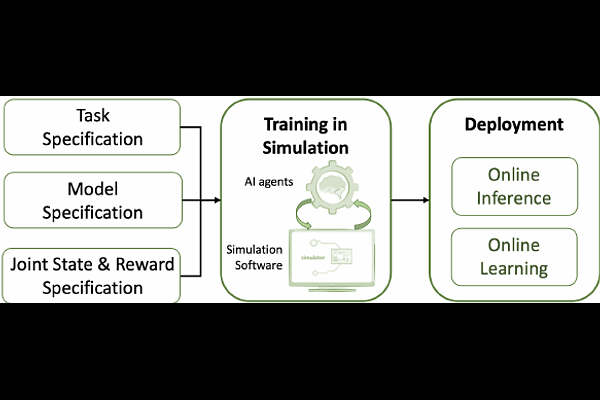
AbstractMulti-Agent Reinforcement Learning (MARL) has achieved significant success in large-scale AI systems and big-data applications such as smart grids, surveillance, etc. Existing advancements in MARL algorithms focus on improving the rewards obtained by introducing various mechanisms for inter-agent cooperation. However, these optimizations are usually compute- and memory-intensive, thus leading to suboptimal speed performance in end-to-end training time. In this work, we analyze the speed performance (i.e., latency-bounded throughput) as the key metric in MARL implementations. Specifically, we first introduce a taxonomy of MARL algorithms from an acceleration perspective categorized by (1) training scheme and (2) communication method. Using our taxonomy, we identify three state-of-the-art MARL algorithms - Multi-Agent Deep Deterministic Policy Gradient (MADDPG), Target-oriented Multi-agent Communication and Cooperation (ToM2C), and Networked Multi-Agent RL (NeurComm) - as target benchmark algorithms, and provide a systematic analysis of their performance bottlenecks on a homogeneous multi-core CPU platform. We justify the need for MARL latency-bounded throughput to be a key performance metric in future literature while also addressing opportunities for parallelization and acceleration.