Exploring Memorization in Fine-tuned Language Models
Exploring Memorization in Fine-tuned Language Models
Shenglai Zeng, Yaxin Li, Jie Ren, Yiding Liu, Han Xu, Pengfei He, Yue Xing, Shuaiqiang Wang, Jiliang Tang, Dawei Yin
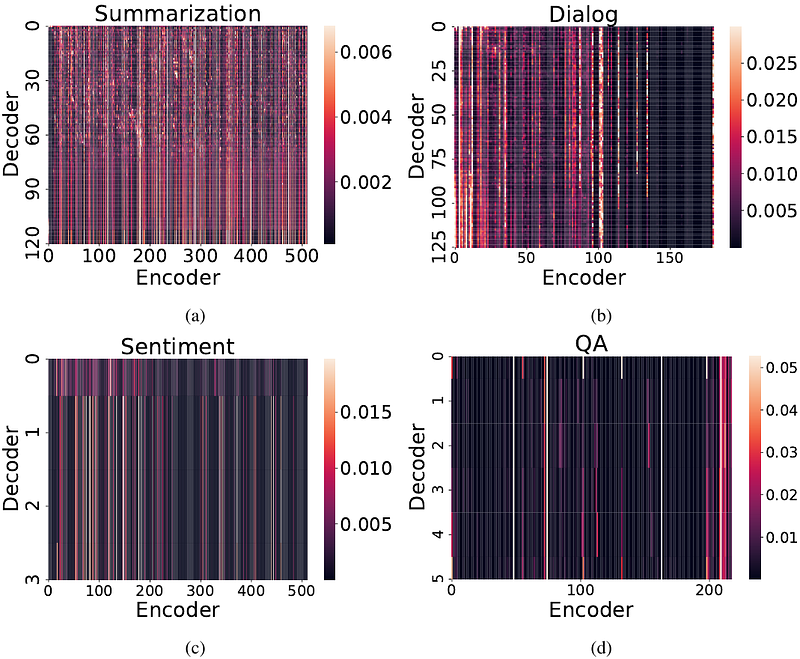
AbstractLLMs have shown great capabilities in various tasks but also exhibited memorization of training data, thus raising tremendous privacy and copyright concerns. While prior work has studied memorization during pre-training, the exploration of memorization during fine-tuning is rather limited. Compared with pre-training, fine-tuning typically involves sensitive data and diverse objectives, thus may bring unique memorization behaviors and distinct privacy risks. In this work, we conduct the first comprehensive analysis to explore LMs' memorization during fine-tuning across tasks. Our studies with open-sourced and our own fine-tuned LMs across various tasks indicate that fine-tuned memorization presents a strong disparity among tasks. We provide an understanding of this task disparity via sparse coding theory and unveil a strong correlation between memorization and attention score distribution. By investigating its memorization behavior, multi-task fine-tuning paves a potential strategy to mitigate fine-tuned memorization.