RAMP: A Flat Nanosecond Optical Network and MPI Operations for Distributed Deep Learning Systems
RAMP: A Flat Nanosecond Optical Network and MPI Operations for Distributed Deep Learning Systems
Alessandro Ottino, Joshua Benjamin, Georgios Zervas
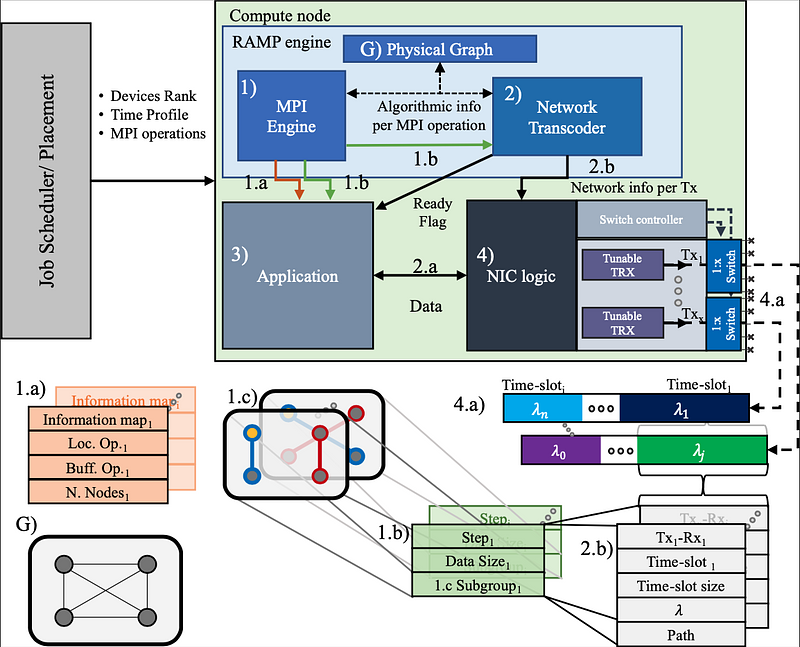
AbstractDistributed deep learning (DDL) systems strongly depend on network performance. Current electronic packet switched (EPS) network architectures and technologies suffer from variable diameter topologies, low-bisection bandwidth and over-subscription affecting completion time of communication and collective operations. We introduce a near-exascale, full-bisection bandwidth, all-to-all, single-hop, all-optical network architecture with nanosecond reconfiguration called RAMP, which supports large-scale distributed and parallel computing systems (12.8~Tbps per node for up to 65,536 nodes). For the first time, a custom RAMP-x MPI strategy and a network transcoder is proposed to run MPI collective operations across the optical circuit switched (OCS) network in a schedule-less and contention-less manner. RAMP achieves 7.6-171$\times$ speed-up in completion time across all MPI operations compared to realistic EPS and OCS counterparts. It can also deliver a 1.3-16$\times$ and 7.8-58$\times$ reduction in Megatron and DLRM training time respectively} while offering 42-53$\times$ and 3.3-12.4$\times$ improvement in energy consumption and cost respectively.