Agent psychometrics: Task-level performance prediction in agentic coding benchmarks
Agent psychometrics: Task-level performance prediction in agentic coding benchmarks
Chris Ge, Daria Kryvosheieva, Daniel Fried, Uzay Girit, Kaivalya Hariharan
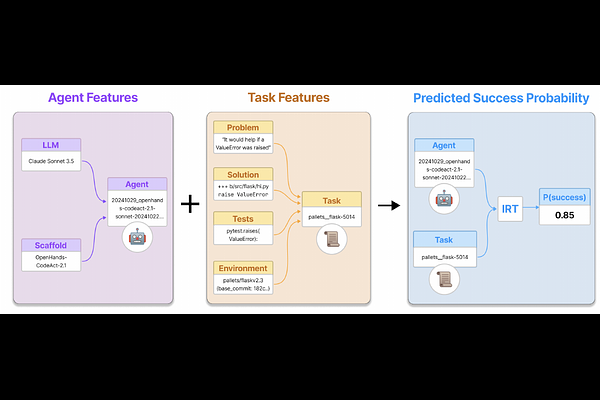
AbstractAs the focus in LLM-based coding shifts from static single-step code generation to multi-step agentic interaction with tools and environments, understanding which tasks will challenge agents and why becomes increasingly difficult. This is compounded by current practice: agent performance is typically measured by aggregate pass rates on benchmarks, but single-number metrics obscure the diversity of tasks within a benchmark. We present a framework for predicting success or failure on individual tasks tailored to the agentic coding regime. Our approach augments Item Response Theory (IRT) with rich features extracted from tasks, including issue statements, repository contexts, solutions, and test cases, and introduces a novel decomposition of agent ability into LLM and scaffold ability components. This parameterization enables us to aggregate evaluation data across heterogeneous leaderboards and accurately predict task-level performance for unseen benchmarks, as well as unseen LLM-scaffold combinations. Our methods have practical utility for benchmark designers, who can better calibrate the difficulty of their new tasks without running computationally expensive agent evaluations.