InstructRetro: Instruction Tuning post Retrieval-Augmented Pretraining
InstructRetro: Instruction Tuning post Retrieval-Augmented Pretraining
Boxin Wang, Wei Ping, Lawrence McAfee, Peng Xu, Bo Li, Mohammad Shoeybi, Bryan Catanzaro
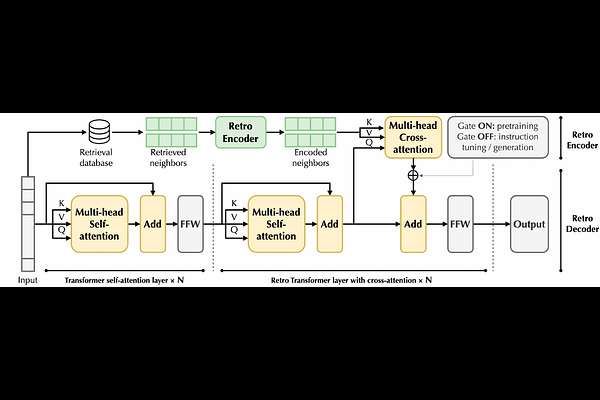
AbstractPretraining auto-regressive large language models (LLMs) with retrieval demonstrates better perplexity and factual accuracy by leveraging external databases. However, the size of existing pretrained retrieval-augmented LLM is still limited (e.g., Retro has 7.5B parameters), which limits the effectiveness of instruction tuning and zero-shot generalization. In this work, we introduce Retro 48B, the largest LLM pretrained with retrieval before instruction tuning. Specifically, we continue to pretrain the 43B GPT model on additional 100 billion tokens using the Retro augmentation method by retrieving from 1.2 trillion tokens. The obtained foundation model, Retro 48B, largely outperforms the original 43B GPT in terms of perplexity. After instruction tuning on Retro, InstructRetro demonstrates significant improvement over the instruction tuned GPT on zero-shot question answering (QA) tasks. Specifically, the average improvement of InstructRetro is 7% over its GPT counterpart across 8 short-form QA tasks, and 10% over GPT across 4 challenging long-form QA tasks. Surprisingly, we find that one can ablate the encoder from InstructRetro architecture and directly use its decoder backbone, while achieving comparable results. We hypothesize that pretraining with retrieval makes its decoder good at incorporating context for QA. Our results highlights the promising direction to obtain a better GPT decoder for QA through continued pretraining with retrieval before instruction tuning.