Scalable Incomplete Multi-View Clustering with Structure Alignment
Scalable Incomplete Multi-View Clustering with Structure Alignment
Yi Wen, Siwei Wang, Ke Liang, Weixuan Liang, Xinhang Wan, Xinwang Liu, Suyuan Liu, Jiyuan Liu, En Zhu
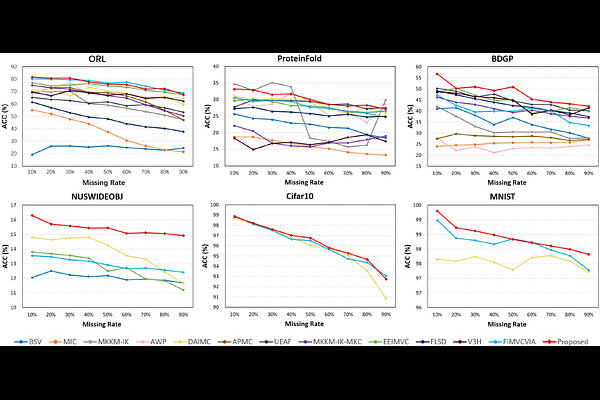
AbstractThe success of existing multi-view clustering (MVC) relies on the assumption that all views are complete. However, samples are usually partially available due to data corruption or sensor malfunction, which raises the research of incomplete multi-view clustering (IMVC). Although several anchor-based IMVC methods have been proposed to process the large-scale incomplete data, they still suffer from the following drawbacks: i) Most existing approaches neglect the inter-view discrepancy and enforce cross-view representation to be consistent, which would corrupt the representation capability of the model; ii) Due to the samples disparity between different views, the learned anchor might be misaligned, which we referred as the Anchor-Unaligned Problem for Incomplete data (AUP-ID). Such the AUP-ID would cause inaccurate graph fusion and degrades clustering performance. To tackle these issues, we propose a novel incomplete anchor graph learning framework termed Scalable Incomplete Multi-View Clustering with Structure Alignment (SIMVC-SA). Specially, we construct the view-specific anchor graph to capture the complementary information from different views. In order to solve the AUP-ID, we propose a novel structure alignment module to refine the cross-view anchor correspondence. Meanwhile, the anchor graph construction and alignment are jointly optimized in our unified framework to enhance clustering quality. Through anchor graph construction instead of full graphs, the time and space complexity of the proposed SIMVC-SA is proven to be linearly correlated with the number of samples. Extensive experiments on seven incomplete benchmark datasets demonstrate the effectiveness and efficiency of our proposed method. Our code is publicly available at https://github.com/wy1019/SIMVC-SA.