Overview of Caching Mechanisms to Improve Hadoop Performance
Overview of Caching Mechanisms to Improve Hadoop Performance
Rana Ghazali, Douglas G. Down
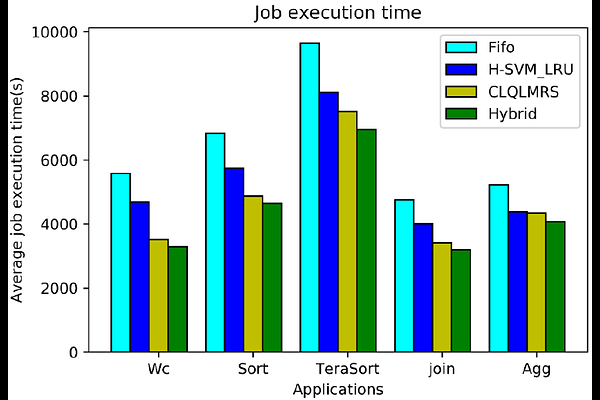
AbstractNowadays distributed computing environments, large amounts of data are generated from different resources with a high velocity, rendering the data difficult to capture, manage, and process within existing relational databases. Hadoop is a tool to store and process large datasets in a parallel manner across a cluster of machines in a distributed environment. Hadoop brings many benefits like flexibility, scalability, and high fault tolerance; however, it faces some challenges in terms of data access time, I/O operation, and duplicate computations resulting in extra overhead, resource wastage, and poor performance. Many researchers have utilized caching mechanisms to tackle these challenges. For example, they have presented approaches to improve data access time, enhance data locality rate, remove repetitive calculations, reduce the number of I/O operations, decrease the job execution time, and increase resource efficiency. In the current study, we provide a comprehensive overview of caching strategies to improve Hadoop performance. Additionally, a novel classification is introduced based on cache utilization. Using this classification, we analyze the impact on Hadoop performance and discuss the advantages and disadvantages of each group. Finally, a novel hybrid approach called Hybrid Intelligent Cache (HIC) that combines the benefits of two methods from different groups, H-SVM-LRU and CLQLMRS, is presented. Experimental results show that our hybrid method achieves an average improvement of 31.2% in job execution time.