Maximizing Confidence Alone Improves Reasoning
Maximizing Confidence Alone Improves Reasoning
Mihir Prabhudesai, Lili Chen, Alex Ippoliti, Katerina Fragkiadaki, Hao Liu, Deepak Pathak
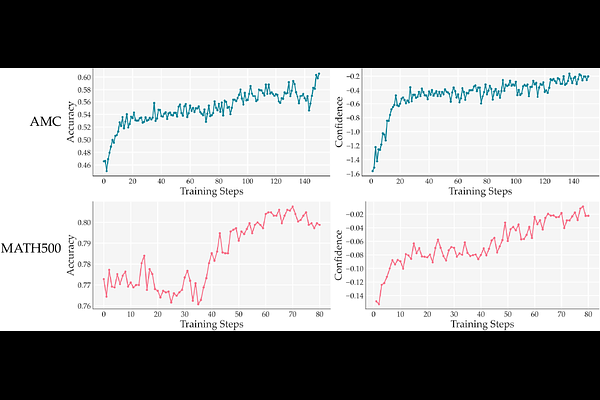
AbstractReinforcement learning (RL) has enabled machine learning models to achieve significant advances in many fields. Most recently, RL has empowered frontier language models to solve challenging math, science, and coding problems. However, central to any RL algorithm is the reward function, and reward engineering is a notoriously difficult problem in any domain. In this paper, we propose RENT: Reinforcement Learning via Entropy Minimization -- a fully unsupervised RL method that requires no external reward or ground-truth answers, and instead uses the model's entropy of its underlying distribution as an intrinsic reward. We find that by reinforcing the chains of thought that yield high model confidence on its generated answers, the model improves its reasoning ability. In our experiments, we showcase these improvements on an extensive suite of commonly-used reasoning benchmarks, including GSM8K, MATH500, AMC, AIME, and GPQA, and models of varying sizes from the Qwen and Mistral families. The generality of our unsupervised learning method lends itself to applicability in a wide range of domains where external supervision is limited or unavailable.