DNNShifter: An Efficient DNN Pruning System for Edge Computing
DNNShifter: An Efficient DNN Pruning System for Edge Computing
Bailey J. Eccles, Philip Rodgers, Peter Kilpatrick, Ivor Spence, Blesson Varghese
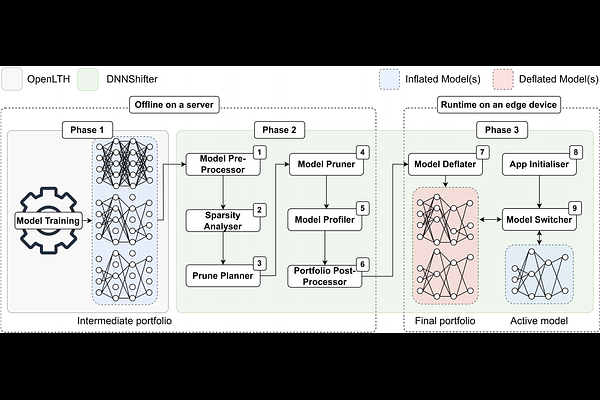
AbstractDeep neural networks (DNNs) underpin many machine learning applications. Production quality DNN models achieve high inference accuracy by training millions of DNN parameters which has a significant resource footprint. This presents a challenge for resources operating at the extreme edge of the network, such as mobile and embedded devices that have limited computational and memory resources. To address this, models are pruned to create lightweight, more suitable variants for these devices. Existing pruning methods are unable to provide similar quality models compared to their unpruned counterparts without significant time costs and overheads or are limited to offline use cases. Our work rapidly derives suitable model variants while maintaining the accuracy of the original model. The model variants can be swapped quickly when system and network conditions change to match workload demand. This paper presents DNNShifter, an end-to-end DNN training, spatial pruning, and model switching system that addresses the challenges mentioned above. At the heart of DNNShifter is a novel methodology that prunes sparse models using structured pruning. The pruned model variants generated by DNNShifter are smaller in size and thus faster than dense and sparse model predecessors, making them suitable for inference at the edge while retaining near similar accuracy as of the original dense model. DNNShifter generates a portfolio of model variants that can be swiftly interchanged depending on operational conditions. DNNShifter produces pruned model variants up to 93x faster than conventional training methods. Compared to sparse models, the pruned model variants are up to 5.14x smaller and have a 1.67x inference latency speedup, with no compromise to sparse model accuracy. In addition, DNNShifter has up to 11.9x lower overhead for switching models and up to 3.8x lower memory utilisation than existing approaches.