MedAI Dialog Corpus (MEDIC): Zero-Shot Classification of Doctor and AI Responses in Health Consultations
MedAI Dialog Corpus (MEDIC): Zero-Shot Classification of Doctor and AI Responses in Health Consultations
Olumide E. Ojo, Olaronke O. Adebanji, Alexander Gelbukh, Hiram Calvo, Anna Feldman
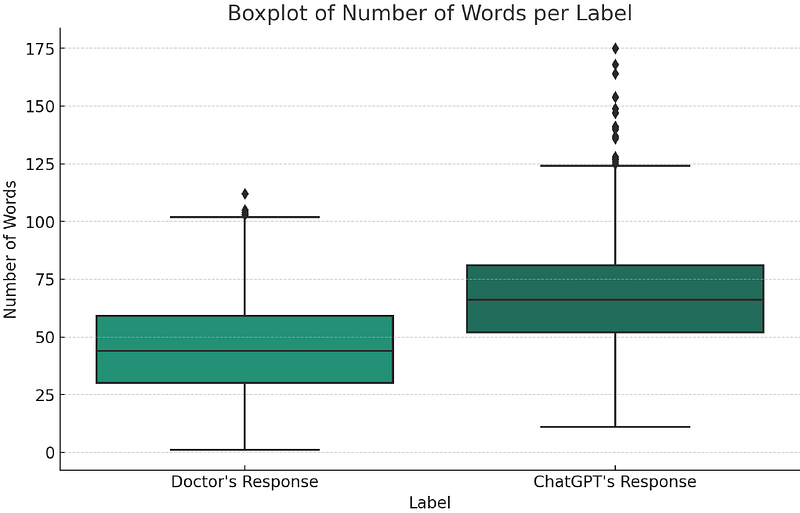
AbstractZero-shot classification has enabled the classification of text into classes that were not seen during training. In this paper, we investigate the effectiveness of pre-trained language models to accurately classify responses from Doctors and AI in health consultations through zero-shot learning. Our study aims to determine whether these models can effectively detect if a text originates from human or AI models without specific corpus training. For our experiments, we collected responses from doctors to patient inquiries about their health and posed the same question/response to AI models. Our findings revealed that while pre-trained language models demonstrate a strong understanding of language generally, they may require specific corpus training or other techniques to achieve accurate classification of doctor- and AI-generated text in healthcare consultations. As a baseline approach, this study shows the limitations of relying solely on zero-shot classification in medical classification tasks. This research lays the groundwork for further research into the field of medical text classification, informing the development of more effective approaches to accurately classify doctor- and AI-generated text in health consultations.