Back to Basics: A Sanity Check on Modern Time Series Classification Algorithms
Back to Basics: A Sanity Check on Modern Time Series Classification Algorithms
Bhaskar Dhariyal, Thach Le Nguyen, Georgiana Ifrim
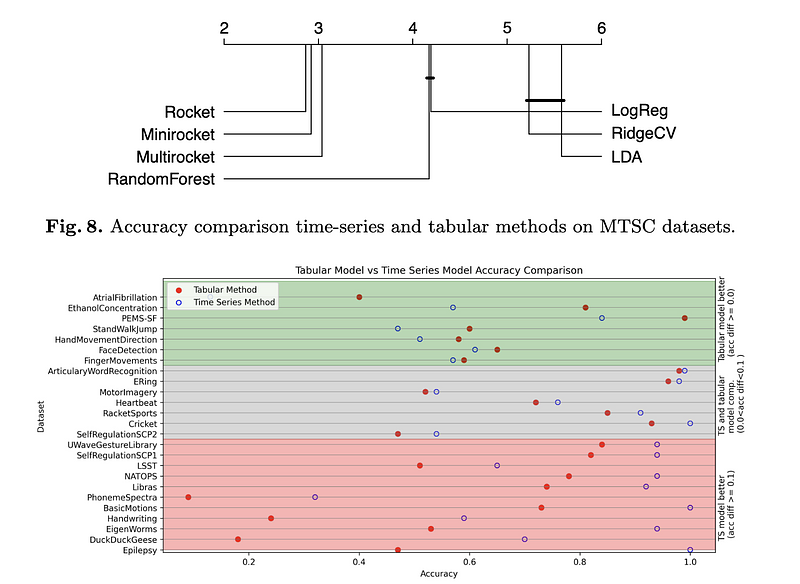
AbstractThe state-of-the-art in time series classification has come a long way, from the 1NN-DTW algorithm to the ROCKET family of classifiers. However, in the current fast-paced development of new classifiers, taking a step back and performing simple baseline checks is essential. These checks are often overlooked, as researchers are focused on establishing new state-of-the-art results, developing scalable algorithms, and making models explainable. Nevertheless, there are many datasets that look like time series at first glance, but classic algorithms such as tabular methods with no time ordering may perform better on such problems. For example, for spectroscopy datasets, tabular methods tend to significantly outperform recent time series methods. In this study, we compare the performance of tabular models using classic machine learning approaches (e.g., Ridge, LDA, RandomForest) with the ROCKET family of classifiers (e.g., Rocket, MiniRocket, MultiRocket). Tabular models are simple and very efficient, while the ROCKET family of classifiers are more complex and have state-of-the-art accuracy and efficiency among recent time series classifiers. We find that tabular models outperform the ROCKET family of classifiers on approximately 19% of univariate and 28% of multivariate datasets in the UCR/UEA benchmark and achieve accuracy within 10 percentage points on about 50% of datasets. Our results suggest that it is important to consider simple tabular models as baselines when developing time series classifiers. These models are very fast, can be as effective as more complex methods and may be easier to understand and deploy.