Verbosity Bias in Preference Labeling by Large Language Models
Verbosity Bias in Preference Labeling by Large Language Models
Keita Saito, Akifumi Wachi, Koki Wataoka, Youhei Akimoto
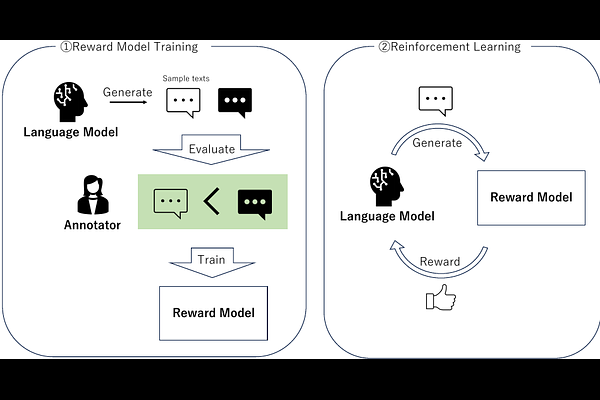
AbstractIn recent years, Large Language Models (LLMs) have witnessed a remarkable surge in prevalence, altering the landscape of natural language processing and machine learning. One key factor in improving the performance of LLMs is alignment with humans achieved with Reinforcement Learning from Human Feedback (RLHF), as for many LLMs such as GPT-4, Bard, etc. In addition, recent studies are investigating the replacement of human feedback with feedback from other LLMs named Reinforcement Learning from AI Feedback (RLAIF). We examine the biases that come along with evaluating LLMs with other LLMs and take a closer look into verbosity bias -- a bias where LLMs sometimes prefer more verbose answers even if they have similar qualities. We see that in our problem setting, GPT-4 prefers longer answers more than humans. We also propose a metric to measure this bias.