ExtractBench: A Benchmark and Evaluation Methodology for Complex Structured Extraction
ExtractBench: A Benchmark and Evaluation Methodology for Complex Structured Extraction
Nick Ferguson, Josh Pennington, Narek Beghian, Aravind Mohan, Douwe Kiela, Sheshansh Agrawal, Thien Hang Nguyen
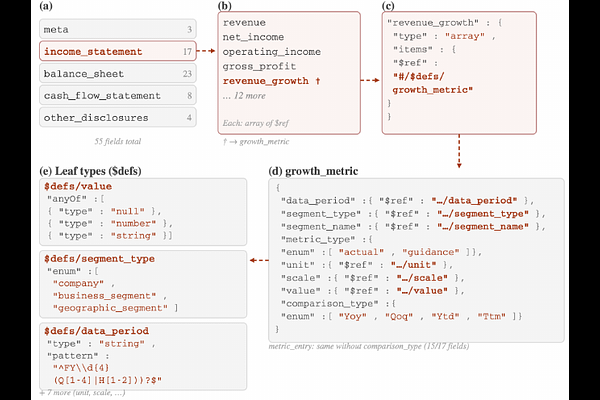
AbstractUnstructured documents like PDFs contain valuable structured information, but downstream systems require this data in reliable, standardized formats. LLMs are increasingly deployed to automate this extraction, making accuracy and reliability paramount. However, progress is bottlenecked by two gaps. First, no end-to-end benchmark evaluates PDF-to-JSON extraction under enterprise-scale schema breadth. Second, no principled methodology captures the semantics of nested extraction, where fields demand different notions of correctness (exact match for identifiers, tolerance for quantities, semantic equivalence for names), arrays require alignment, and omission must be distinguished from hallucination. We address both gaps with ExtractBench, an open-source benchmark and evaluation framework for PDF-to-JSON structured extraction. The benchmark pairs 35 PDF documents with JSON Schemas and human-annotated gold labels across economically valuable domains, yielding 12,867 evaluatable fields spanning schema complexities from tens to hundreds of fields. The evaluation framework treats the schema as an executable specification: each field declares its scoring metric. Baseline evaluations reveal that frontier models (GPT-5/5.2, Gemini-3 Flash/Pro, Claude 4.5 Opus/Sonnet) remain unreliable on realistic schemas. Performance degrades sharply with schema breadth, culminating in 0% valid output on a 369-field financial reporting schema across all tested models. We release ExtractBench at https://github.com/ContextualAI/extract-bench.