Adaptive approximation of monotone functions
Adaptive approximation of monotone functions
Pierre Gaillard Thoth, Sébastien Gerchinovitz IMT, Étienne de Montbrun TSE-R
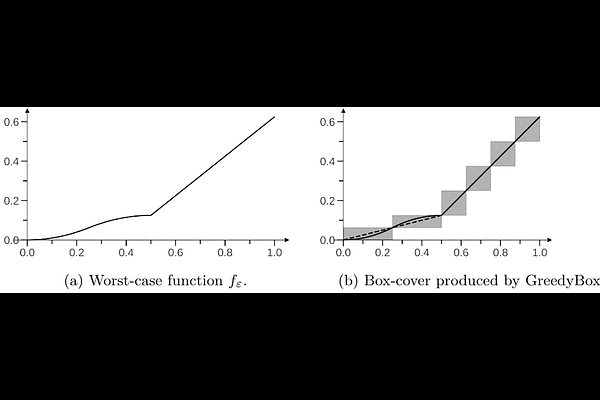
AbstractWe study the classical problem of approximating a non-decreasing function $f: \mathcal{X} \to \mathcal{Y}$ in $L^p(\mu)$ norm by sequentially querying its values, for known compact real intervals $\mathcal{X}$, $\mathcal{Y}$ and a known probability measure $\mu$ on $\cX$. For any function~$f$ we characterize the minimum number of evaluations of $f$ that algorithms need to guarantee an approximation $\hat{f}$ with an $L^p(\mu)$ error below $\epsilon$ after stopping. Unlike worst-case results that hold uniformly over all $f$, our complexity measure is dependent on each specific function $f$. To address this problem, we introduce GreedyBox, a generalization of an algorithm originally proposed by Novak (1992) for numerical integration. We prove that GreedyBox achieves an optimal sample complexity for any function $f$, up to logarithmic factors. Additionally, we uncover results regarding piecewise-smooth functions. Perhaps as expected, the $L^p(\mu)$ error of GreedyBox decreases much faster for piecewise-$C^2$ functions than predicted by the algorithm (without any knowledge on the smoothness of $f$). A simple modification even achieves optimal minimax approximation rates for such functions, which we compute explicitly. In particular, our findings highlight multiple performance gaps between adaptive and non-adaptive algorithms, smooth and piecewise-smooth functions, as well as monotone or non-monotone functions. Finally, we provide numerical experiments to support our theoretical results.