How Re-sampling Helps for Long-Tail Learning?
How Re-sampling Helps for Long-Tail Learning?
Jiang-Xin Shi, Tong Wei, Yuke Xiang, Yu-Feng Li
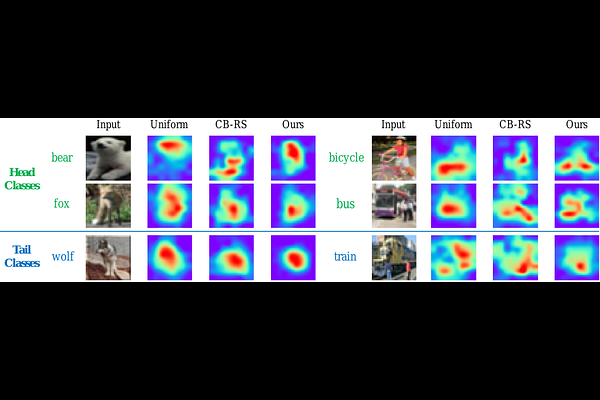
AbstractLong-tail learning has received significant attention in recent years due to the challenge it poses with extremely imbalanced datasets. In these datasets, only a few classes (known as the head classes) have an adequate number of training samples, while the rest of the classes (known as the tail classes) are infrequent in the training data. Re-sampling is a classical and widely used approach for addressing class imbalance issues. Unfortunately, recent studies claim that re-sampling brings negligible performance improvements in modern long-tail learning tasks. This paper aims to investigate this phenomenon systematically. Our research shows that re-sampling can considerably improve generalization when the training images do not contain semantically irrelevant contexts. In other scenarios, however, it can learn unexpected spurious correlations between irrelevant contexts and target labels. We design experiments on two homogeneous datasets, one containing irrelevant context and the other not, to confirm our findings. To prevent the learning of spurious correlations, we propose a new context shift augmentation module that generates diverse training images for the tail class by maintaining a context bank extracted from the head-class images. Experiments demonstrate that our proposed module can boost the generalization and outperform other approaches, including class-balanced re-sampling, decoupled classifier re-training, and data augmentation methods. The source code is available at https://www.lamda.nju.edu.cn/code_CSA.ashx.