Variance of ML-based software fault predictors: are we really improving fault prediction?
Variance of ML-based software fault predictors: are we really improving fault prediction?
Xhulja Shahini, Domenic Bubel, Andreas Metzger
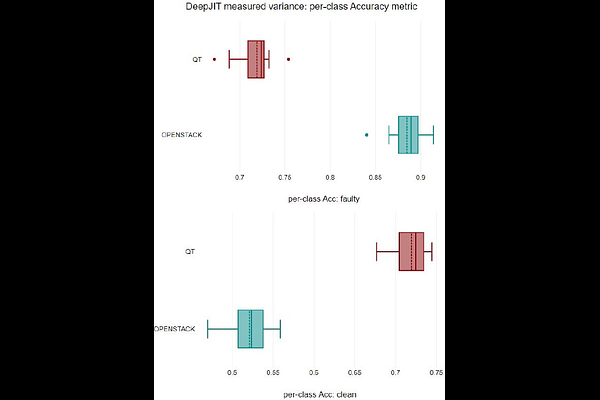
AbstractSoftware quality assurance activities become increasingly difficult as software systems become more and more complex and continuously grow in size. Moreover, testing becomes even more expensive when dealing with large-scale systems. Thus, to effectively allocate quality assurance resources, researchers have proposed fault prediction (FP) which utilizes machine learning (ML) to predict fault-prone code areas. However, ML algorithms typically make use of stochastic elements to increase the prediction models' generalizability and efficiency of the training process. These stochastic elements, also known as nondeterminism-introducing (NI) factors, lead to variance in the training process and as a result, lead to variance in prediction accuracy and training time. This variance poses a challenge for reproducibility in research. More importantly, while fault prediction models may have shown good performance in the lab (e.g., often-times involving multiple runs and averaging outcomes), high variance of results can pose the risk that these models show low performance when applied in practice. In this work, we experimentally analyze the variance of a state-of-the-art fault prediction approach. Our experimental results indicate that NI factors can indeed cause considerable variance in the fault prediction models' accuracy. We observed a maximum variance of 10.10% in terms of the per-class accuracy metric. We thus, also discuss how to deal with such variance.