We Don't Need No Adam, All We Need Is EVE: On The Variance of Dual Learning Rate And Beyond
We Don't Need No Adam, All We Need Is EVE: On The Variance of Dual Learning Rate And Beyond
Afshin Khadangi
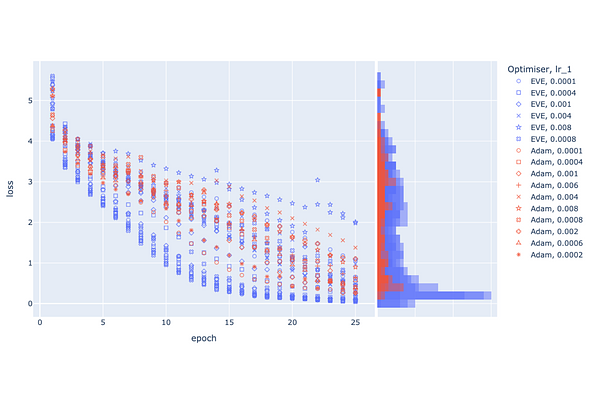
AbstractIn the rapidly advancing field of deep learning, optimising deep neural networks is paramount. This paper introduces a novel method, Enhanced Velocity Estimation (EVE), which innovatively applies different learning rates to distinct components of the gradients. By bifurcating the learning rate, EVE enables more nuanced control and faster convergence, addressing the challenges associated with traditional single learning rate approaches. Utilising a momentum term that adapts to the learning landscape, the method achieves a more efficient navigation of the complex loss surface, resulting in enhanced performance and stability. Extensive experiments demonstrate that EVE significantly outperforms existing optimisation techniques across various benchmark datasets and architectures.