MathCoder-VL: Bridging Vision and Code for Enhanced Multimodal Mathematical Reasoning
MathCoder-VL: Bridging Vision and Code for Enhanced Multimodal Mathematical Reasoning
Ke Wang, Junting Pan, Linda Wei, Aojun Zhou, Weikang Shi, Zimu Lu, Han Xiao, Yunqiao Yang, Houxing Ren, Mingjie Zhan, Hongsheng Li
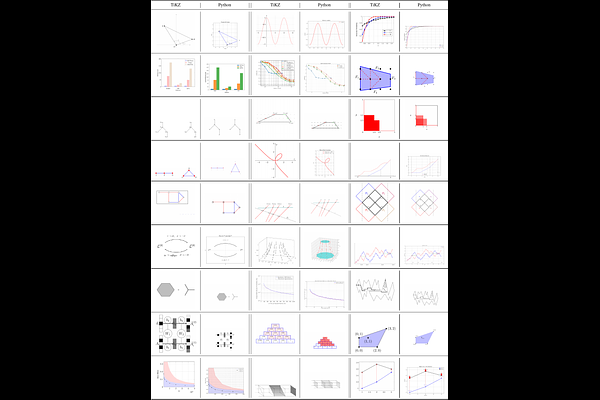
AbstractNatural language image-caption datasets, widely used for training Large Multimodal Models, mainly focus on natural scenarios and overlook the intricate details of mathematical figures that are critical for problem-solving, hindering the advancement of current LMMs in multimodal mathematical reasoning. To this end, we propose leveraging code as supervision for cross-modal alignment, since code inherently encodes all information needed to generate corresponding figures, establishing a precise connection between the two modalities. Specifically, we co-develop our image-to-code model and dataset with model-in-the-loop approach, resulting in an image-to-code model, FigCodifier and ImgCode-8.6M dataset, the largest image-code dataset to date. Furthermore, we utilize FigCodifier to synthesize novel mathematical figures and then construct MM-MathInstruct-3M, a high-quality multimodal math instruction fine-tuning dataset. Finally, we present MathCoder-VL, trained with ImgCode-8.6M for cross-modal alignment and subsequently fine-tuned on MM-MathInstruct-3M for multimodal math problem solving. Our model achieves a new open-source SOTA across all six metrics. Notably, it surpasses GPT-4o and Claude 3.5 Sonnet in the geometry problem-solving subset of MathVista, achieving improvements of 8.9% and 9.2%. The dataset and models will be released at https://github.com/mathllm/MathCoder.