Towards Desiderata-Driven Design of Visual Counterfactual Explainers
Towards Desiderata-Driven Design of Visual Counterfactual Explainers
Sidney Bender, Jan Herrmann, Klaus-Robert Müller, Grégoire Montavon
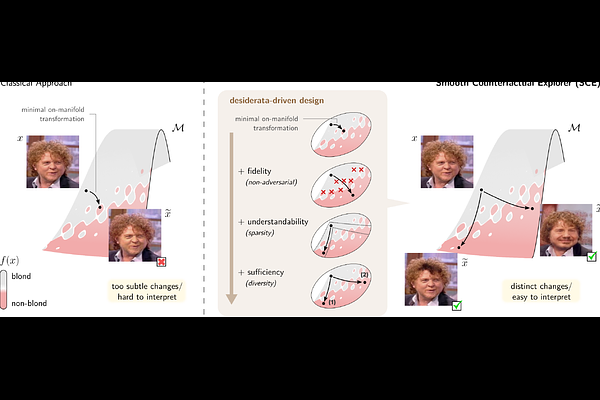
AbstractVisual counterfactual explainers (VCEs) are a straightforward and promising approach to enhancing the transparency of image classifiers. VCEs complement other types of explanations, such as feature attribution, by revealing the specific data transformations to which a machine learning model responds most strongly. In this paper, we argue that existing VCEs focus too narrowly on optimizing sample quality or change minimality; they fail to consider the more holistic desiderata for an explanation, such as fidelity, understandability, and sufficiency. To address this shortcoming, we explore new mechanisms for counterfactual generation and investigate how they can help fulfill these desiderata. We combine these mechanisms into a novel 'smooth counterfactual explorer' (SCE) algorithm and demonstrate its effectiveness through systematic evaluations on synthetic and real data.