AntifakePrompt: Prompt-Tuned Vision-Language Models are Fake Image Detectors
AntifakePrompt: Prompt-Tuned Vision-Language Models are Fake Image Detectors
You-Ming Chang, Chen Yeh, Wei-Chen Chiu, Ning Yu
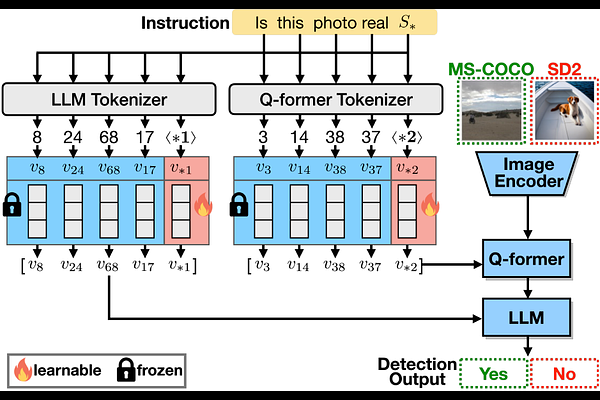
AbstractDeep generative models can create remarkably photorealistic fake images while raising concerns about misinformation and copyright infringement, known as deepfake threats. Deepfake detection technique is developed to distinguish between real and fake images, where the existing methods typically learn classifiers in the image domain or various feature domains. However, the generalizability of deepfake detection against emerging and more advanced generative models remains challenging. In this paper, being inspired by the zero-shot advantages of Vision-Language Models (VLMs), we propose a novel approach using VLMs (e.g. InstructBLIP) and prompt tuning techniques to improve the deepfake detection accuracy over unseen data. We formulate deepfake detection as a visual question answering problem, and tune soft prompts for InstructBLIP to answer the real/fake information of a query image. We conduct full-spectrum experiments on datasets from 3 held-in and 13 held-out generative models, covering modern text-to-image generation, image editing and image attacks. Results demonstrate that (1) the deepfake detection accuracy can be significantly and consistently improved (from 58.8% to 91.31%, in average accuracy over unseen data) using pretrained vision-language models with prompt tuning; (2) our superior performance is at less cost of trainable parameters, resulting in an effective and efficient solution for deepfake detection. Code and models can be found at https://github.com/nctu-eva-lab/AntifakePrompt.