Large language models for aspect-based sentiment analysis
Large language models for aspect-based sentiment analysis
Paul F. Simmering, Paavo Huoviala
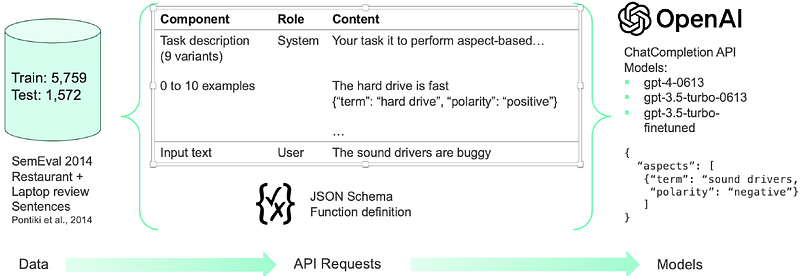
AbstractLarge language models (LLMs) offer unprecedented text completion capabilities. As general models, they can fulfill a wide range of roles, including those of more specialized models. We assess the performance of GPT-4 and GPT-3.5 in zero shot, few shot and fine-tuned settings on the aspect-based sentiment analysis (ABSA) task. Fine-tuned GPT-3.5 achieves a state-of-the-art F1 score of 83.8 on the joint aspect term extraction and polarity classification task of the SemEval-2014 Task 4, improving upon InstructABSA [@scaria_instructabsa_2023] by 5.7%. However, this comes at the price of 1000 times more model parameters and thus increased inference cost. We discuss the the cost-performance trade-offs of different models, and analyze the typical errors that they make. Our results also indicate that detailed prompts improve performance in zero-shot and few-shot settings but are not necessary for fine-tuned models. This evidence is relevant for practioners that are faced with the choice of prompt engineering versus fine-tuning when using LLMs for ABSA.