UltraLogic: Enhancing LLM Reasoning through Large-Scale Data Synthesis and Bipolar Float Reward
UltraLogic: Enhancing LLM Reasoning through Large-Scale Data Synthesis and Bipolar Float Reward
Yile Liu, Yixian Liu, Zongwei Li, Yufei Huang, Xinhua Feng, Zhichao Hu, Jinglu Hu, Jianfeng Yan, Fengzong Lian, Yuhong Liu
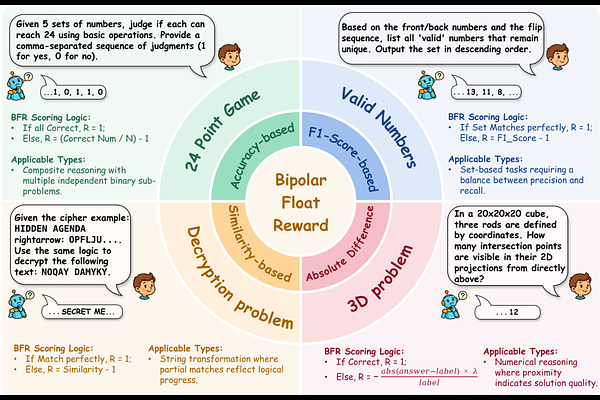
AbstractWhile Large Language Models (LLMs) have demonstrated significant potential in natural language processing , complex general-purpose reasoning requiring multi-step logic, planning, and verification remains a critical bottleneck. Although Reinforcement Learning with Verifiable Rewards (RLVR) has succeeded in specific domains , the field lacks large-scale, high-quality, and difficulty-calibrated data for general reasoning. To address this, we propose UltraLogic, a framework that decouples the logical core of a problem from its natural language expression through a Code-based Solving methodology to automate high-quality data production. The framework comprises hundreds of unique task types and an automated calibration pipeline across ten difficulty levels. Furthermore, to mitigate binary reward sparsity and the Non-negative Reward Trap, we introduce the Bipolar Float Reward (BFR) mechanism, utilizing graded penalties to effectively distinguish perfect responses from those with logical flaws. Our experiments demonstrate that task diversity is the primary driver for reasoning enhancement , and that BFR, combined with a difficulty matching strategy, significantly improves training efficiency, guiding models toward global logical optima.