Towards Understanding Modality Interaction in Multimodal Language Models via Partial Information Decomposition
Towards Understanding Modality Interaction in Multimodal Language Models via Partial Information Decomposition
Wanlong Fang, Tianle Zhang, Wen Tao, Alvin Chan
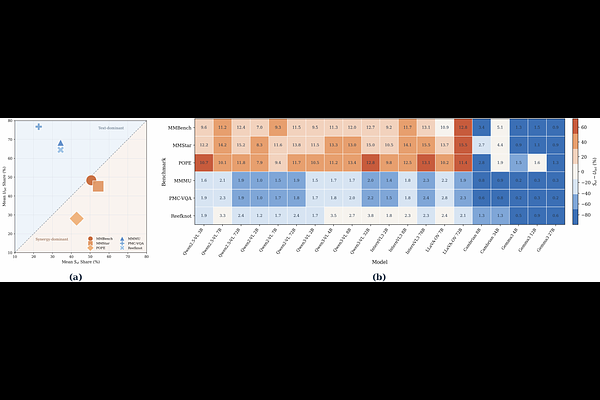
AbstractUnderstanding modality interaction in multimodal large language models (MLLMs) is central to reliable deployment. We introduce Partial Information Decomposition (PID) as a decision-level framework that separates unique, redundant, and synergistic contributions of sensory and linguistic inputs, beyond representation alignment and outcome-based evaluation. Across vision--language benchmarks, PID reveals recurring modality-use profiles: reasoning and grounding-oriented tasks tend to exhibit high synergy, whereas expert and knowledge-oriented tasks show stronger language-unique reliance. These profiles generalize across model families and predict sensitivity to modality-level interventions. We further extend PID to tri-modal systems with Sensory PID, treating language as a control variable to decompose video--audio information gain. Applied to omni-modal models, Sensory PID reveals a sensory synergy bottleneck dominated by visual information even on audio--visual fusion tasks. Finally, PID-guided reweighting provides initial evidence for improving multimodal reasoning and grounding performance.