Direct Unsupervised Denoising
Direct Unsupervised Denoising
Benjamin Salmon, Alexander Krull
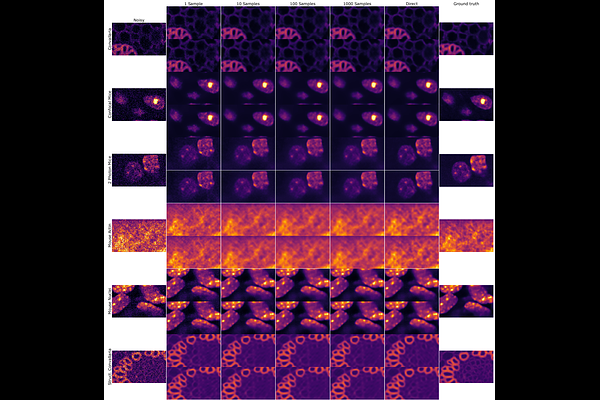
AbstractTraditional supervised denoisers are trained using pairs of noisy input and clean target images. They learn to predict a central tendency of the posterior distribution over possible clean images. When, e.g., trained with the popular quadratic loss function, the network's output will correspond to the minimum mean square error (MMSE) estimate. Unsupervised denoisers based on Variational AutoEncoders (VAEs) have succeeded in achieving state-of-the-art results while requiring only unpaired noisy data as training input. In contrast to the traditional supervised approach, unsupervised denoisers do not directly produce a single prediction, such as the MMSE estimate, but allow us to draw samples from the posterior distribution of clean solutions corresponding to the noisy input. To approximate the MMSE estimate during inference, unsupervised methods have to create and draw a large number of samples - a computationally expensive process - rendering the approach inapplicable in many situations. Here, we present an alternative approach that trains a deterministic network alongside the VAE to directly predict a central tendency. Our method achieves results that surpass the results achieved by the unsupervised method at a fraction of the computational cost.