Effect of Attention and Self-Supervised Speech Embeddings on Non-Semantic Speech Tasks
Effect of Attention and Self-Supervised Speech Embeddings on Non-Semantic Speech Tasks
Payal Mohapatra, Akash Pandey, Yueyuan Sui, Qi Zhu
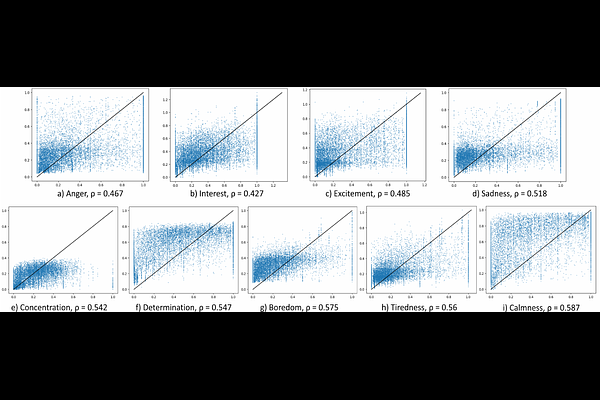
AbstractHuman emotion understanding is pivotal in making conversational technology mainstream. We view speech emotion understanding as a perception task which is a more realistic setting. With varying contexts (languages, demographics, etc.) different share of people perceive the same speech segment as a non-unanimous emotion. As part of the ACM Multimedia 2023 Computational Paralinguistics ChallengE (ComParE) in the EMotion Share track, we leverage their rich dataset of multilingual speakers and multi-label regression target of 'emotion share' or perception of that emotion. We demonstrate that the training scheme of different foundation models dictates their effectiveness for tasks beyond speech recognition, especially for non-semantic speech tasks like emotion understanding. This is a very complex task due to multilingual speakers, variability in the target labels, and inherent imbalance in the regression dataset. Our results show that HuBERT-Large with a self-attention-based light-weight sequence model provides 4.6% improvement over the reported baseline.