Impact of Visual Context on Noisy Multimodal NMT: An Empirical Study for English to Indian Languages
Impact of Visual Context on Noisy Multimodal NMT: An Empirical Study for English to Indian Languages
Baban Gain, Dibyanayan Bandyopadhyay, Samrat Mukherjee, Chandranath Adak, Asif Ekbal
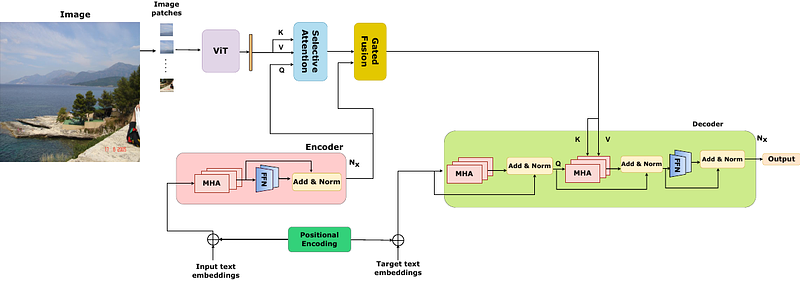
AbstractThe study investigates the effectiveness of utilizing multimodal information in Neural Machine Translation (NMT). While prior research focused on using multimodal data in low-resource scenarios, this study examines how image features impact translation when added to a large-scale, pre-trained unimodal NMT system. Surprisingly, the study finds that images might be redundant in this context. Additionally, the research introduces synthetic noise to assess whether images help the model deal with textual noise. Multimodal models slightly outperform text-only models in noisy settings, even with random images. The study's experiments translate from English to Hindi, Bengali, and Malayalam, outperforming state-of-the-art benchmarks significantly. Interestingly, the effect of visual context varies with source text noise: no visual context works best for non-noisy translations, cropped image features are optimal for low noise, and full image features work better in high-noise scenarios. This sheds light on the role of visual context, especially in noisy settings, opening up a new research direction for Noisy Neural Machine Translation in multimodal setups. The research emphasizes the importance of combining visual and textual information for improved translation in various environments.