Development and external validation of a lung cancer risk estimation tool using gradient-boosting
Development and external validation of a lung cancer risk estimation tool using gradient-boosting
Pierre-Louis Benveniste, Julie Alberge, Lei Xing, Jean-Emmanuel Bibault
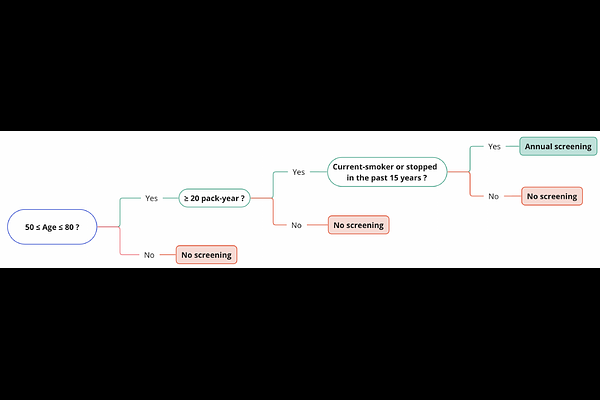
AbstractLung cancer is a significant cause of mortality worldwide, emphasizing the importance of early detection for improved survival rates. In this study, we propose a machine learning (ML) tool trained on data from the PLCO Cancer Screening Trial and validated on the NLST to estimate the likelihood of lung cancer occurrence within five years. The study utilized two datasets, the PLCO (n=55,161) and NLST (n=48,595), consisting of comprehensive information on risk factors, clinical measurements, and outcomes related to lung cancer. Data preprocessing involved removing patients who were not current or former smokers and those who had died of causes unrelated to lung cancer. Additionally, a focus was placed on mitigating bias caused by censored data. Feature selection, hyper-parameter optimization, and model calibration were performed using XGBoost, an ensemble learning algorithm that combines gradient boosting and decision trees. The ML model was trained on the pre-processed PLCO dataset and tested on the NLST dataset. The model incorporated features such as age, gender, smoking history, medical diagnoses, and family history of lung cancer. The model was well-calibrated (Brier score=0.044). ROC-AUC was 82% on the PLCO dataset and 70% on the NLST dataset. PR-AUC was 29% and 11% respectively. When compared to the USPSTF guidelines for lung cancer screening, our model provided the same recall with a precision of 13.1% vs. 9.3% on the PLCO dataset and 3.2% vs. 3.1% on the NLST dataset. The developed ML tool provides a freely available web application for estimating the likelihood of developing lung cancer within five years. By utilizing risk factors and clinical data, individuals can assess their risk and make informed decisions regarding lung cancer screening. This research contributes to the efforts in early detection and prevention strategies, aiming to reduce lung cancer-related mortality rates.