Scale-Adaptive Feature Aggregation for Efficient Space-Time Video Super-Resolution
Scale-Adaptive Feature Aggregation for Efficient Space-Time Video Super-Resolution
Zhewei Huang, Ailin Huang, Xiaotao Hu, Chen Hu, Jun Xu, Shuchang Zhou
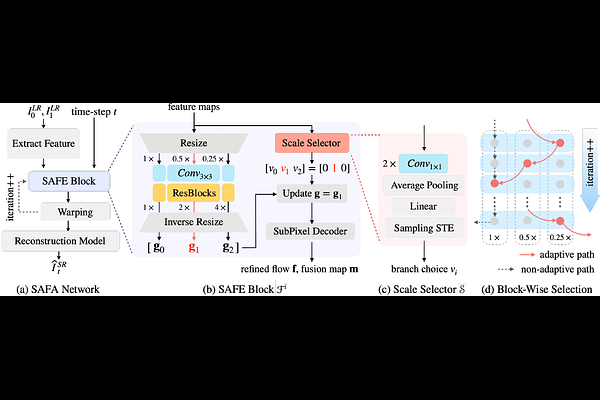
AbstractThe Space-Time Video Super-Resolution (STVSR) task aims to enhance the visual quality of videos, by simultaneously performing video frame interpolation (VFI) and video super-resolution (VSR). However, facing the challenge of the additional temporal dimension and scale inconsistency, most existing STVSR methods are complex and inflexible in dynamically modeling different motion amplitudes. In this work, we find that choosing an appropriate processing scale achieves remarkable benefits in flow-based feature propagation. We propose a novel Scale-Adaptive Feature Aggregation (SAFA) network that adaptively selects sub-networks with different processing scales for individual samples. Experiments on four public STVSR benchmarks demonstrate that SAFA achieves state-of-the-art performance. Our SAFA network outperforms recent state-of-the-art methods such as TMNet and VideoINR by an average improvement of over 0.5dB on PSNR, while requiring less than half the number of parameters and only 1/3 computational costs.