Learning When to Attend: Conditional Memory Access for Long-Context LLMs
Learning When to Attend: Conditional Memory Access for Long-Context LLMs
Sakshi Choudhary, Aditya Chattopadhyay, Luca Zancato, Elvis Nunez, Matthew Trager, Wei Xia, Stefano Soatto
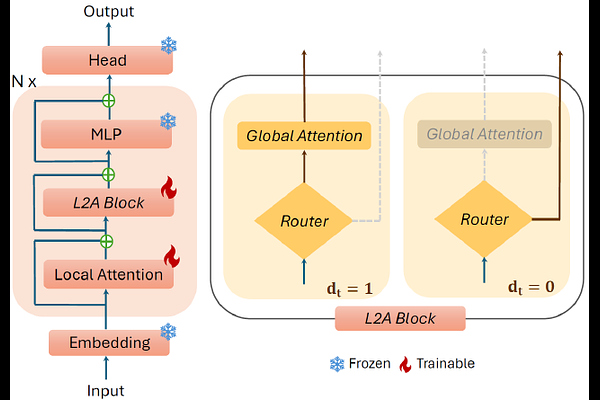
AbstractLanguage models struggle to generalize beyond pretraining context lengths, limiting long-horizon reasoning and retrieval. Continued pretraining on long-context data can help but is expensive due to the quadratic scaling of Attention. We observe that most tokens do not require (Global) Attention over the entire sequence and can rely on local context. Based on this, we propose L2A (Learning To Attend), a layer that enables conditional (token-wise) long-range memory access by deciding when to invoke global attention. We evaluate L2A on Qwen 2.5 and Qwen 3 models, extending their effective context length from 32K to 128K tokens. L2A matches the performance of standard long-context training to within 3% while skipping Global Attention for $\sim$80% of tokens, outperforming prior baselines. We also design custom Triton kernels to efficiently implement this token-wise conditional Attention on GPUs, achieving up to $\sim$2x improvements in training throughput and time-to-first-token over FlashAttention. Moreover, L2A enables post-training pruning of highly sparse Global Attention layers, reducing KV cache memory by up to 50% with negligible performance loss.