Sparse Suffix and LCP Array: Simple, Direct, Small, and Fast
Sparse Suffix and LCP Array: Simple, Direct, Small, and Fast
Lorraine A. K. Ayad, Grigorios Loukides, Solon P. Pissis, Hilde Verbeek
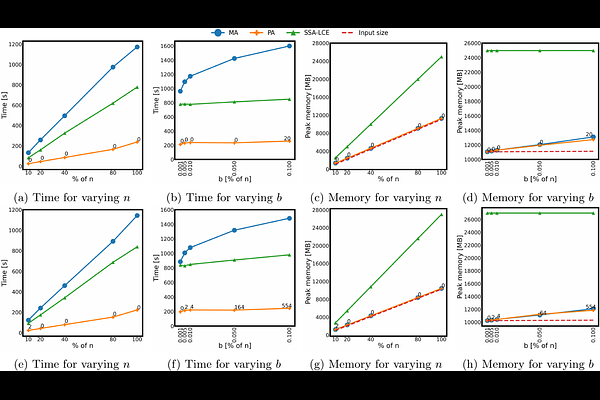
AbstractSparse suffix sorting is the problem of sorting $b=o(n)$ suffixes of a string of length $n$. Efficient sparse suffix sorting algorithms have existed for more than a decade. Despite the multitude of works and their justified claims for applications in text indexing, the existing algorithms have not been employed by practitioners. Arguably this is because there are no simple, direct, and efficient algorithms for sparse suffix array construction. We provide two new algorithms for constructing the sparse suffix and LCP arrays that are simultaneously simple, direct, small, and fast. In particular, our algorithms are: simple in the sense that they can be implemented using only basic data structures; direct in the sense that the output arrays are not a byproduct of constructing the sparse suffix tree or an LCE data structure; fast in the sense that they run in $\mathcal{O}(n\log b)$ time, in the worst case, or in $\mathcal{O}(n)$ time, when the total number of suffixes with an LCP value greater than $2^{\lfloor \log \frac{n}{b} \rfloor + 1}-1$ is in $\mathcal{O}(b/\log b)$, matching the time of the optimal yet much more complicated algorithms [Gawrychowski and Kociumaka, SODA 2017; Birenzwige et al., SODA 2020]; and small in the sense that they can be implemented using only $8b+o(b)$ machine words. Our algorithms are simplified, yet non-trivial, space-efficient adaptations of the Monte Carlo algorithm by I et al. for constructing the sparse suffix tree in $\mathcal{O}(n\log b)$ time [STACS 2014]. We also provide proof-of-concept experiments to justify our claims on simplicity and efficiency.