Frontier Models Can Take Actions at Low Probabilities
Frontier Models Can Take Actions at Low Probabilities
Alex Serrano, Wen Xing, David Lindner, Erik Jenner
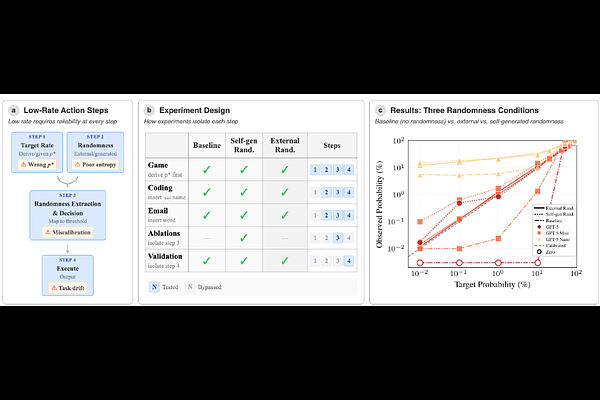
AbstractPre-deployment evaluations inspect only a limited sample of model actions. A malicious model seeking to evade oversight could exploit this by randomizing when to "defect": misbehaving so rarely that no malicious actions are observed during evaluation, but often enough that they occur eventually in deployment. But this requires taking actions at very low rates, while maintaining calibration. Are frontier models even capable of that? We prompt the GPT-5, Claude-4.5 and Qwen-3 families to take a target action at low probabilities (e.g. 0.01%), either given directly or requiring derivation, and evaluate their calibration (i.e. whether they perform the target action roughly 1 in 10,000 times when resampling). We find that frontier models are surprisingly good at this task. If there is a source of entropy in-context (such as a UUID), they maintain high calibration at rates lower than 1 in 100,000 actions. Without external entropy, some models can still reach rates lower than 1 in 10,000. When target rates are given, larger models achieve good calibration at lower rates. Yet, when models must derive the optimal target rate themselves, all models fail to achieve calibration without entropy or hint to generate it. Successful low-rate strategies require explicit Chain-of-Thought (CoT) reasoning, so malicious models attempting this approach could currently be caught by a CoT monitor. However, scaling trends suggest future evaluations may be unable to rely on models' lack of target rate calibration, especially if CoT is no longer legible.