Audio compression-assisted feature extraction for voice replay attack detection
Audio compression-assisted feature extraction for voice replay attack detection
Xiangyu Shi, Yuhao Luo, Li Wang, Haorui He, Hao Li, Lei Wang, Zhizheng Wu
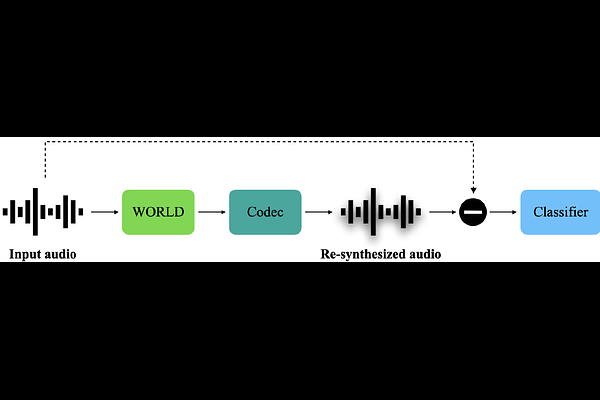
AbstractReplay attack is one of the most effective and simplest voice spoofing attacks. Detecting replay attacks is challenging, according to the Automatic Speaker Verification Spoofing and Countermeasures Challenge 2021 (ASVspoof 2021), because they involve a loudspeaker, a microphone, and acoustic conditions (e.g., background noise). One obstacle to detecting replay attacks is finding robust feature representations that reflect the channel noise information added to the replayed speech. This study proposes a feature extraction approach that uses audio compression for assistance. Audio compression compresses audio to preserve content and speaker information for transmission. The missed information after decompression is expected to contain content- and speaker-independent information (e.g., channel noise added during the replay process). We conducted a comprehensive experiment with a few data augmentation techniques and 3 classifiers on the ASVspoof 2021 physical access (PA) set and confirmed the effectiveness of the proposed feature extraction approach. To the best of our knowledge, the proposed approach achieves the lowest EER at 22.71% on the ASVspoof 2021 PA evaluation set.