Rephrase, Augment, Reason: Visual Grounding of Questions for Vision-Language Models
Rephrase, Augment, Reason: Visual Grounding of Questions for Vision-Language Models
Archiki Prasad, Elias Stengel-Eskin, Mohit Bansal
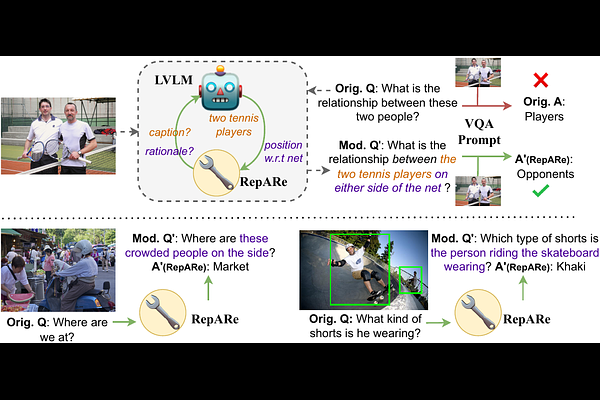
AbstractAn increasing number of vision-language tasks can be handled with little to no training, i.e., in a zero and few-shot manner, by marrying large language models (LLMs) to vision encoders, resulting in large vision-language models (LVLMs). While this has huge upsides, such as not requiring training data or custom architectures, how an input is presented to a LVLM can have a major impact on zero-shot model performance. In particular, inputs phrased in an underspecified way can result in incorrect answers due to factors like missing visual information, complex implicit reasoning, or linguistic ambiguity. Therefore, adding visually grounded information to the input as a preemptive clarification should improve model performance by reducing underspecification, e.g., by localizing objects and disambiguating references. Similarly, in the VQA setting, changing the way questions are framed can make them easier for models to answer. To this end, we present Rephrase, Augment and Reason (RepARe), a gradient-free framework that extracts salient details about the image using the underlying LVLM as a captioner and reasoner, in order to propose modifications to the original question. We then use the LVLM's confidence over a generated answer as an unsupervised scoring function to select the rephrased question most likely to improve zero-shot performance. Focusing on two visual question answering tasks, we show that RepARe can result in a 3.85% (absolute) increase in zero-shot performance on VQAv2 and a 6.41% point increase on A-OKVQA. Additionally, we find that using gold answers for oracle question candidate selection achieves a substantial gain in VQA accuracy by up to 14.41%. Through extensive analysis, we demonstrate that outputs from RepARe increase syntactic complexity, and effectively utilize vision-language interaction and the frozen language model in LVLMs.