Quantifying Privacy Risks of Prompts in Visual Prompt Learning
Quantifying Privacy Risks of Prompts in Visual Prompt Learning
Yixin Wu, Rui Wen, Michael Backes, Pascal Berrang, Mathias Humbert, Yun Shen, Yang Zhang
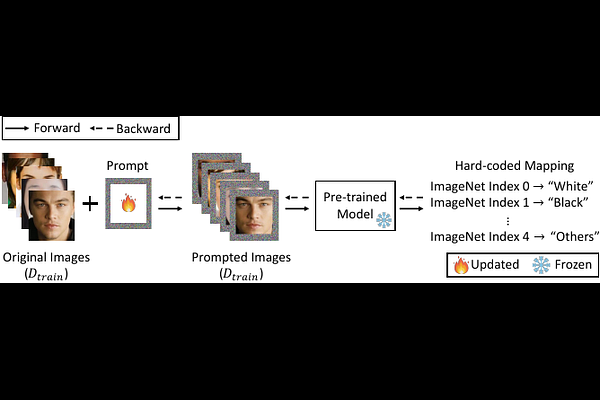
AbstractLarge-scale pre-trained models are increasingly adapted to downstream tasks through a new paradigm called prompt learning. In contrast to fine-tuning, prompt learning does not update the pre-trained model's parameters. Instead, it only learns an input perturbation, namely prompt, to be added to the downstream task data for predictions. Given the fast development of prompt learning, a well-generalized prompt inevitably becomes a valuable asset as significant effort and proprietary data are used to create it. This naturally raises the question of whether a prompt may leak the proprietary information of its training data. In this paper, we perform the first comprehensive privacy assessment of prompts learned by visual prompt learning through the lens of property inference and membership inference attacks. Our empirical evaluation shows that the prompts are vulnerable to both attacks. We also demonstrate that the adversary can mount a successful property inference attack with limited cost. Moreover, we show that membership inference attacks against prompts can be successful with relaxed adversarial assumptions. We further make some initial investigations on the defenses and observe that our method can mitigate the membership inference attacks with a decent utility-defense trade-off but fails to defend against property inference attacks. We hope our results can shed light on the privacy risks of the popular prompt learning paradigm. To facilitate the research in this direction, we will share our code and models with the community.