From Zero to Hero: Harnessing Transformers for Biomedical Named Entity Recognition in Zero- and Few-shot Contexts
From Zero to Hero: Harnessing Transformers for Biomedical Named Entity Recognition in Zero- and Few-shot Contexts
Miloš Košprdić, Nikola Prodanović, Adela Ljajić, Bojana Bašaragin, Nikola Milošević
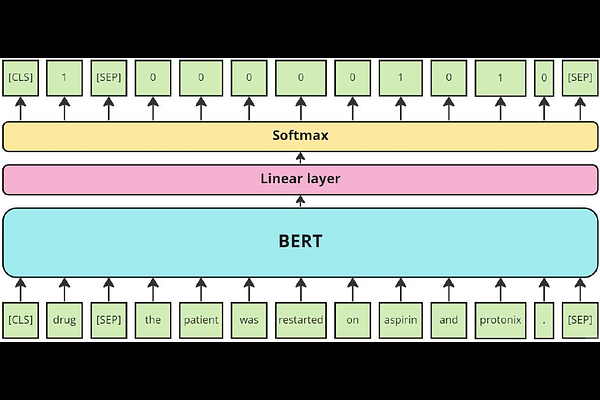
AbstractSupervised named entity recognition (NER) in the biomedical domain depends on large sets of annotated texts with the given named entities. The creation of such datasets can be time-consuming and expensive, while extraction of new entities requires additional annotation tasks and retraining the model. To address these challenges, this paper proposes a method for zero- and few-shot NER in the biomedical domain. The method is based on transforming the task of multi-class token classification into binary token classification and pre-training on a large amount of datasets and biomedical entities, which allow the model to learn semantic relations between the given and potentially novel named entity labels. We have achieved average F1 scores of 35.44% for zero-shot NER, 50.10% for one-shot NER, 69.94% for 10-shot NER, and 79.51% for 100-shot NER on 9 diverse evaluated biomedical entities with fine-tuned PubMedBERT-based model. The results demonstrate the effectiveness of the proposed method for recognizing new biomedical entities with no or limited number of examples, outperforming previous transformer-based methods, and being comparable to GPT3-based models using models with over 1000 times fewer parameters. We make models and developed code publicly available.