Developing a Scalable Benchmark for Assessing Large Language Models in Knowledge Graph Engineering
Developing a Scalable Benchmark for Assessing Large Language Models in Knowledge Graph Engineering
Lars-Peter Meyer, Johannes Frey, Kurt Junghanns, Felix Brei, Kirill Bulert, Sabine Gründer-Fahrer, Michael Martin
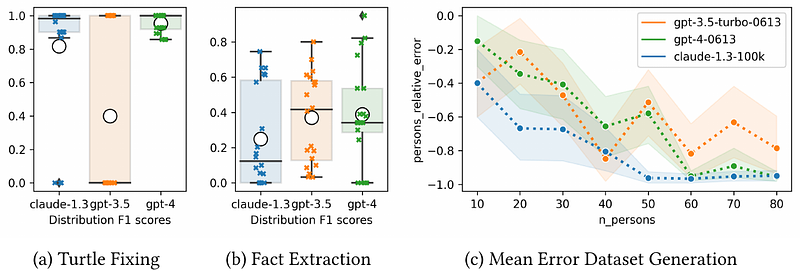
AbstractAs the field of Large Language Models (LLMs) evolves at an accelerated pace, the critical need to assess and monitor their performance emerges. We introduce a benchmarking framework focused on knowledge graph engineering (KGE) accompanied by three challenges addressing syntax and error correction, facts extraction and dataset generation. We show that while being a useful tool, LLMs are yet unfit to assist in knowledge graph generation with zero-shot prompting. Consequently, our LLM-KG-Bench framework provides automatic evaluation and storage of LLM responses as well as statistical data and visualization tools to support tracking of prompt engineering and model performance.