DyMoE: Dynamic Expert Orchestration with Mixed-Precision Quantization for Efficient MoE Inference on Edge
DyMoE: Dynamic Expert Orchestration with Mixed-Precision Quantization for Efficient MoE Inference on Edge
Yuegui Huang, Zhiyuan Fang, Weiqi Luo, Ruoyu Wu, Wuhui Chen, Zibin Zheng
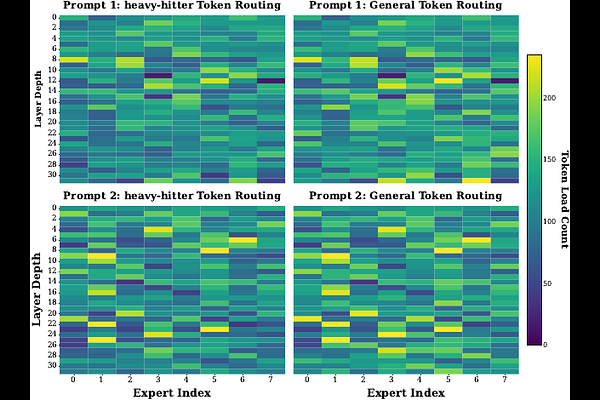
AbstractDespite the computational efficiency of MoE models, the excessive memory footprint and I/O overhead inherent in multi-expert architectures pose formidable challenges for real-time inference on resource-constrained edge platforms. While existing static methods struggle with a rigid latency-accuracy trade-off, we observe that expert importance is highly skewed and depth-dependent. Motivated by these insights, we propose DyMoE, a dynamic mixed-precision quantization framework designed for high-performance edge inference. Leveraging insights into expert importance skewness and depth-dependent sensitivity, DyMoE introduces: (1) importance-aware prioritization to dynamically quantize experts at runtime; (2) depth-adaptive scheduling to preserve semantic integrity in critical layers; and (3) look-ahead prefetching to overlap I/O stalls. Experimental results on commercial edge hardware show that DyMoE reduces Time-to-First-Token (TTFT) by 3.44x-22.7x and up to a 14.58x speedup in Time-Per-Output-Token (TPOT) compared to state-of-the-art offloading baselines, enabling real-time, accuracy-preserving MoE inference on resource-constrained edge devices.