FMMRec: Fairness-aware Multimodal Recommendation
FMMRec: Fairness-aware Multimodal Recommendation
Weixin Chen, Li Chen, Yongxin Ni, Yuhan Zhao, Fajie Yuan, Yongfeng Zhang
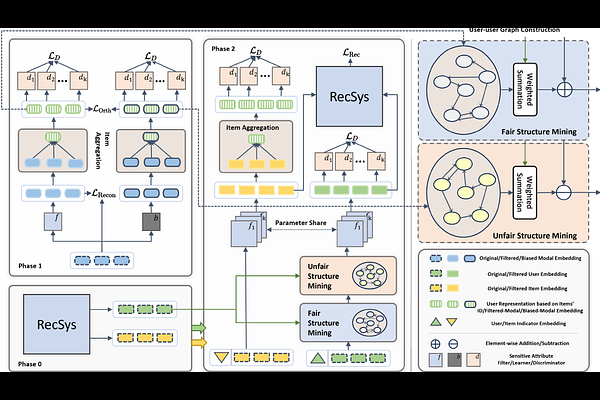
AbstractRecently, multimodal recommendations have gained increasing attention for effectively addressing the data sparsity problem by incorporating modality-based representations. Although multimodal recommendations excel in accuracy, the introduction of different modalities (e.g., images, text, and audio) may expose more users' sensitive information (e.g., gender and age) to recommender systems, resulting in potentially more serious unfairness issues. Despite many efforts on fairness, existing fairness-aware methods are either incompatible with multimodal scenarios, or lead to suboptimal fairness performance due to neglecting sensitive information of multimodal content. To achieve counterfactual fairness in multimodal recommendations, we propose a novel fairness-aware multimodal recommendation approach (dubbed as FMMRec) to disentangle the sensitive and non-sensitive information from modal representations and leverage the disentangled modal representations to guide fairer representation learning. Specifically, we first disentangle biased and filtered modal representations by maximizing and minimizing their sensitive attribute prediction ability respectively. With the disentangled modal representations, we mine the modality-based unfair and fair (corresponding to biased and filtered) user-user structures for enhancing explicit user representation with the biased and filtered neighbors from the corresponding structures, followed by adversarially filtering out sensitive information. Experiments on two real-world public datasets demonstrate the superiority of our FMMRec relative to the state-of-the-art baselines. Our source code is available at https://anonymous.4open.science/r/FMMRec.